[딥러닝강의] GPU 와 딥러닝 소프트웨어

CPU vs. GPU
왜 딥러닝에서 CPU 가 아닌 GPU 를 사용할까? GPU 의 원래 목적은 그래픽을 rendering 하는 것이다. GPU 를 만드는 회사는 크게 NVIDIA 와 AMD 로 나뉜다. 여러 커뮤니티에서 NVIDIA 와 AMD 중에 무엇이 더 나은지 논쟁을 한다. 하지만 딥러닝 측면에서는 NVIDIA 의 GPU 가 더욱 좋다. AMD GPU 는 딥러닝 목적으로 사용하기 힘들다. 따라서 딥러닝에서 GPU 를 말하면 대부분 하나의 회사 NVIDIA 의 GPU 를 의미한다.
Rendering 이란?
평면인 그림에 형태·위치·조명 등 외부의 정보에 따라 다르게 나타나는 그림자 색상 농도 등을 고려하면서 실감나는 3차원 화상을 만들어내는 과정 또는 그러한 기법을 일컫는다. 즉, 평면적으로 보이는 물체에 그림자나 농도의 변화 등을 주어 입체감이 들게 함으로써 사실감을 추가하는 컴퓨터그래픽상의 과정이 곧 렌더링이다. [네이버 지식백과] 렌더링 [rendering]
CPU 와 GPU 의 차이

1) 코어의 종류와 숫자
CPU 는 GPU 보다 더 적은 코어를 갖고 있지만 각각의 코어가 GPU 보다 더 강력한 컴퓨팅 파워를 갖고 있다. 따라서 CPU 는 순차적인 작업 (Sequential task) 에 더 강점이 있다. 반면 GPU 는 CPU 보다 코어수는 많지만 각각의 코어가 GPU 보다 더 성능이 낮기 때문에 병렬적인 작업 (Paralell task) 에 더 강점이 있다. 현재 PC 에서 사용되는 CPU 의 코어는 보통 4~10개 정도이며 hyperthreading 기술을 통해 thread 를 2배 정도 늘릴 수 있다. 예를 들어 8 코어 16 threads CPU 의 경우, 병렬적으로 16개의 task 를 수행할 수 있다는 뜻이다. 반면, 예를 들어 NVIDIA 의 Tital XP GPU 의 경우 3840 코어를 갖고 있다. 또 최근 출시된 2080 TI 의 경우 4,352 개의 코어를 갖고 있다. threading 을 감안하더라도 CPU와 GPU 의 코어 수의 차이는 200 배 이상이다.
2) 메모리
CPU 와 GPU 의 중요한 차이 중 하나는 바로 메모리를 어떻게 사용하는지에 관한 것이다. CPU 는 캐시 메모리가 있지만 대부분의 시스템과 공유된 메모리를 사용한다. PC 의 경우 8GB, 16GB RAM 이 일반적인 메모리의 종류이다. GPU 의 경우 시스템과 메모리를 공유할 수도 있지, 이 경우 GPU 와 메모리 사이의 Bottleneck 이 생기기 때문에 성능이 낮아진다. 따라서 GPU 는 GPU card 내에 자체의 메모리가 존재한다. 예를 들어 Tital XP GPU 의 경우 12 GB 의 메모리를 갖고 있다.
CPU 의 강점은 갖는 것은 여러가지 일 (음악 감상, 영화 감상, 딥러닝, 게임 등)을 할 수 있으며, 순차적인 처리를 빠르게 할 수 있다는 것이다. 반면, GPU 는 여러가지 일을 다 잘하진 못해도 병렬화를 할 수 있다면, 이를 빠르게 처리할 수 있다. 병렬화 가능한 일 중 하나가 바로 행렬 곱 (Matrix multiplication) 이다.
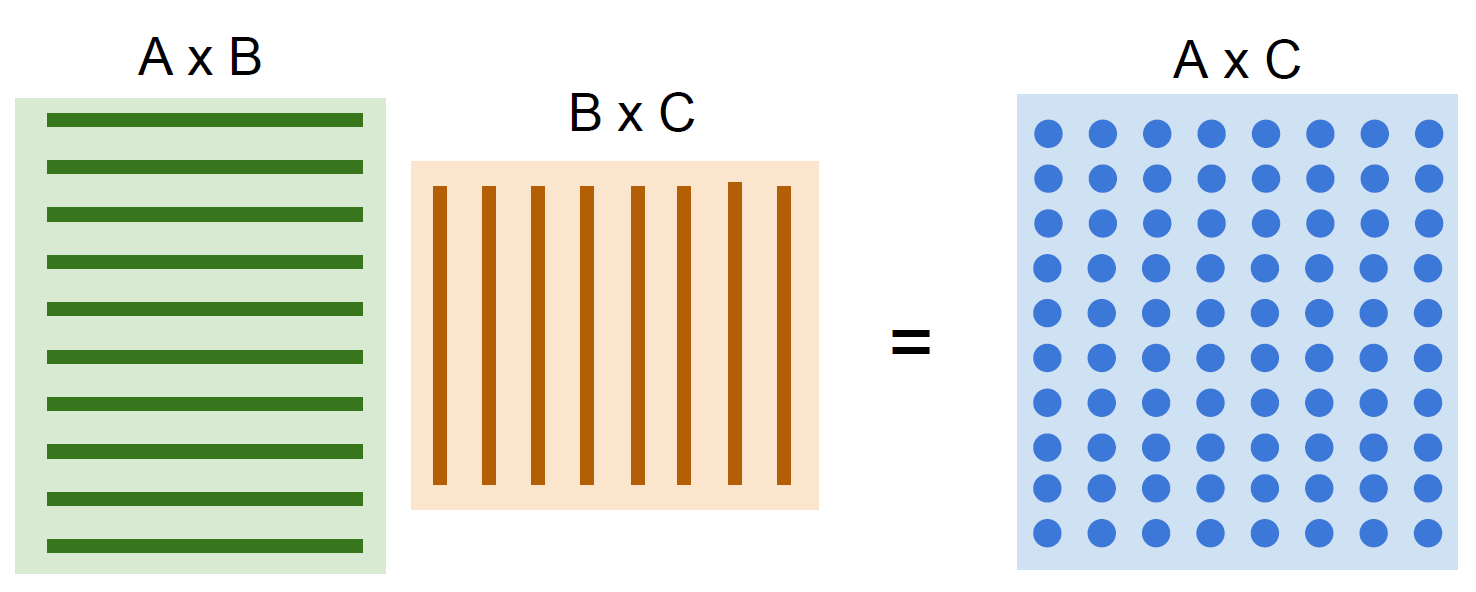
행과 열의 곱을 각각의 GPU 코어에서 처리 후 이를 합친다면 순차적으로 처리하는 것보다 더 빠르게 수행할 수 있을 것이다. GPU 를 이용한 프로그래밍을 하는 방법은 NVIDIA 의 CUDA 라이브러리를 사용하는 것이다. CUDA 를 이용하면 C, C++ 등의 언어로 GPU 프로그래밍을 할 수 있다. 또한 CUDA 보다 high-level API 로 cuBLAS, cuDNN 등 이 있다. high-level API 의 경우 CUDA 를 기반으로 행렬 연산, 딥러닝 등을 구현하는 것에 초점을 맞추어져 있기 때문에 이러한 작업들에 GPU 를 더욱 쉽게 이용할 수 있다. 하지만 CUDA 를 사용한 프로그래밍은 구현하기가 쉽지 않다. 예를 들어 캐시 메모리와 같은 메모리 계층 구조를 잘 이용하지 않으면 효율적인 코드를 작성하기 어렵다.
따라서 딥러닝을 위해서 CUDA 코드를 처음부터 작성해서 이용하지 않는다. 먼저 NVIDIA 에서 CUDA 를 활용하기 위한 high-level API (cuDNN) 를 만들어 놓았기 때문에 이를 이용하면 되기 때문이고, 또한 cuDNN 을 활용한 다양한 딥러닝 프레임워크들이 이미 나와있기 때문이다.
딥러닝 프레임워크
| 이름 | 단체 |
| Caffe2 | |
| PyTorch | |
| TensorFlow | |
| CNTK | Microsoft |
| Paddle | Baidu |
| MXNet | Amazon |
최근 딥러닝 프레임워크는 빠르게 생겨나고 있다. Tensorflow (Keras) 와 PyTorch 가 최근 가장 많이 사용되는 딥러닝 라이브러리가 볼 수 있다. 최근 MXNet 기반 Computer Vision toolkit 인 GluonCV 도 ICCV 에서 발표되는 등 많은 발전이 있는듯하다. GluonCV 는 컴퓨터 비전 분야의 State-of-the-art 를 사용하기 쉽게 만든 MXnet 의 high-level 라이브러리로 볼 수 있다.
딥러닝 프레임워크를 사용하면 우리는 딥러닝을 효율적으로 구현할 수 있다. 상세하게는 아래와 같은 장점이 있다.
1) 딥러닝 모델을 쉽게 만들 수 있다
2) Gradient 를 빠르게 구할 수 있다.
3) GPU 이용을 쉽게하고 효율적으로 동작할 수 있다 (cuDNN, cuBLAS 를 wrapping 해서 구현 → 효율 좋음).
파이토치 (Pytorch)
파이토치 (https://pytorch.org/) 도 위와 같은 이유로 사용되는 대표적인 딥러닝 프레임워크 중 하나이며 최근 많은 인기를 얻고 있다. 파이토치가 인기를 얻게 된 이유는 기술을 단순화 시켜서 사용하도록 만든 사용 편리성과 함께, '동적 계산 그래프 (Dynamic computational graph)' 를 사용한다는 점이다. 텐서플로우의 경우 정적 계산 그래프 (Static computational graph) 으로 한 번 모델을 만든 후, 여러번 돌리는 방식인 반면, 동적 계산 그래프트는 한 번의 forward path 마다 새로운 그래프를 다시 그린다.

동적 계산 그래프 (Dynamic computational graph)
동적 계산 그래프는 어떤 장점을 가질까? 동적 계산 그래프는 복잡한 아키텍쳐를 구축할 때 더욱 유연하다. 예를 들어, RNN 을 활용한 Image captioning 의 경우 input 에 따라 output sequence (텍스트) 의 길이가 달라진다. 따라서 computational graph 가 input 이미지에 따라 동적으로 변한다는 것이다. 이 경우 forward path 마다 구조가 바뀌는 것이 더 효율적이므로 동적 계산 그래프가 더욱 적합하다.

이와 비슷한 Visual Question Answering (VQS) 분야에 Neuromodule 도 동적 계산 그래프가 적합한 예이다. Neuromodule 은 "이미지" 와 "질문" 두 가지를 입력하면 답변을 위한 custom architecture 를 만들고 답을 출력하고자 하는 모델이다. 예를 들어, 고양이 사진을 주고 "고양이의 색깔은?" 과 같은 질문을 던지는 것이다. 이 경우에도 마찬가지로 네트워크가 동적으로 구성되어야 할 것이다. 어떤 사진을 주고 "이 이미지에서 고양이의 수가 강아지의 수보다 많은가?" 라는 질문을 던지면 앞선 네트워크와는 다르게 구성되어야 한다. 이처럼 동적 계산 그래프를 활용하면 다양한 네트워크를 구성할 수 있다.
파이토치는 연구를 위한 목적으로 만들어진 라이브러리이다. 그래서 요청에 따라 빠르게 응답해야하는 프로덕트 용으로는 적합하지 않을 수 있다. 하지만 Open Neural Network Exchange (https://onnx.ai/) 라는 새로운 프로젝트가 나오면서 이런 제약이 줄어들고 있다. onnx 는 머신러닝 모델의 interoperability 를 위한 프로젝트로 모델을 ONNX Format 로 export 한 후 다른 환경에서 import 할 수 있도록 한다. 이를 활용하면 파이토치 모델을 프로덕션용 Caffe2 모델로 변환해서 배포할 수 있다. ONNX Format 은 파이토치 외에도 CNTK, MXNet, 텐서플로, 케라스, Scikit-Learn 에도 활용할 수 있다.
파이토치의 설치
환경 : Ubuntu 16.04, Jupyter Lab (with JupyterHub), Python 3.8, Cuda
1) 파이썬 가상 환경 (virtual environment) 생성 & Jupyter Lab 등록
conda create --name pytorch python==3.8
source activate pytorch
pip install ipykernel
python -m ipykernel install --name pytorch
2) CUDA version check
nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2017 NVIDIA Corporation
Built on Fri_Sep__1_21:08:03_CDT_2017
Cuda compilation tools, release 9.0, V9.0.176
3) Install Pytorch
pytorch 홈페이지에서 환경을 클릭하면 설치할 수 있는 커맨드를 출력해준다. CUDA 9.0 을 사용하고 있는데, CUDA 9.2 를 선택해서 나온 커맨드로 설치해도 무방한듯 하다.

conda install pytorch torchvision cudatoolkit=9.2 -c pytorch
설치 완료 후 주피터 랩에서 pytorch kernel 을 실행 후, import pytorch 로 임포트가 잘 되는 것을 확인하자.
Reference
- 파이토치로 시작하는 딥러닝 (비슈누 수브라마니안) 1장, 2장
- https://www.youtube.com/watch?v=6SlgtELqOWc&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=8
'Soft skills > Lecture' 카테고리의 다른 글
| [딥러닝 강의] [1] 데이터 기반 이미지 분류 (Data-driven Image Classification) (1) | 2020.01.23 |
|---|
