하둡과 응용 프레임워크 2) 하둡 실행 환경 (YARN, Tez, Spark)
이전 포스팅에서 Map reduce 프레임워크의 한계에 대해 설명하고, 이를 보완하기 위하여 YARN, Tez, Spark 등이 사용된다는 것에 대해 간단하게 언급하였다. 하둡 아키텍쳐에 대해 다시 remind 를 해보자.
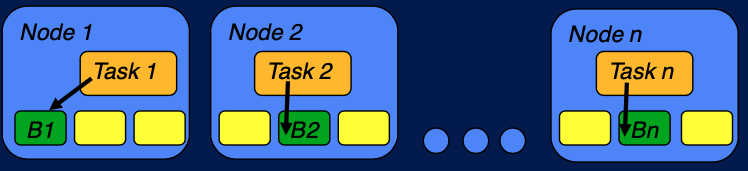
위 그림과 같이 데이터가 node 에 분산되어 저장되어있고, task 가 data node 에 할당되어 처리를 한 후에, 이 결과를 merge 하는 것이 하둡이 어떤 job 을 실행하는 방법이다. 이것이 이전 포스팅에서 언급한 '계산을 데이터로 보내는 것' (computation to data) 의 개념이라고 볼 수 있다. 이러한 방법은 불가능한 것을 가능할 수 있고, 무엇보다 더욱 효율적으로 (빠르게) job 을 처리할 수 있다. 병렬적으로 수행할 수 있고, 데이터의 이동이 최소화되기 때문이다. 하지만 문제는, MapReduce execution framwork 는 Map reduce paradigm 을 구현할 수 있는 application 에만 유용하다. 어떤 application 이 map reduce 를 통해 구현할 수 없는 경우에 문제가 생긴다. 이를 보완하기 위하여 YARN, Tez, Spark 등이 사용된다.
Next Generation Execution Framworks
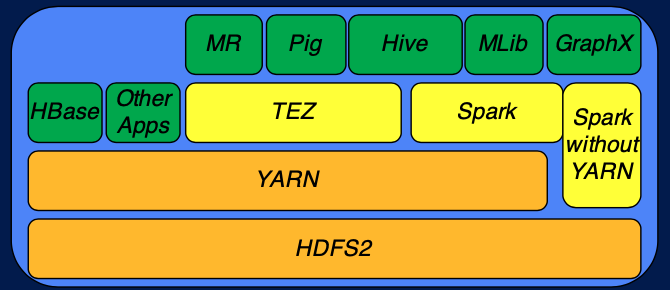
YARN 은 기본적인 Hadoop 의 execution engine 이다. 이 위에 YARN 위에서 동작하는 HBase 와 같은 application 이 있다. 또한 YARN 위에서는 Tez 와 Spark 와 같은 다른 framework가 올라갈 수도 있다. Pig 나 Hive 같은 application 은 TEZ 와 Spark (Hive 의 경우 TEZ와 Spark 모두 이용) 위에서 동작한다. 또한 Spark 는 YARN 없이도 동작할 수 있는 execution framework 이다.
Tez 의 특징은 dataflow graph 를 지원하고, custom data type 을 지원한다. 따라서 맵 리듀스 프레임워크에서 처럼 모든 데이터의 입출력이 key-value pair 로 이루어져야하는 제약이 없다. Tez 를 활용하는 것의 장점은 자원을 효율적으로 관리하고 복잡한 태스크를 DAG (directed acyclic graph) 를 활용해서 실행할 수 있다는 것이다.
Hive on Tez example
Hive 는 backend execution engine 으로 Tez 를 이용하는 것을 지원한다. 예를 들어 아래 코드를 보자.
SELECT a.vendor, COUNT(*), AVG(c.cost) FROM a
JOIN b ON (a.id = b.id)
JOIN c ON (a.itemid = c.itemid)
GROUP BY a.vendor1) Original Hadoop MapReduce 를 사용한 해법

위의 쿼리는 여러개의 map reduce job 으로 나뉘어진다. 하나의 map reduce job 이 다른 job 의 인풋이 되고, 이것들이 조합이 되어 최종적인 쿼리의 결과를 가져올 수 있다.
2) Tez 를 사용한 해법
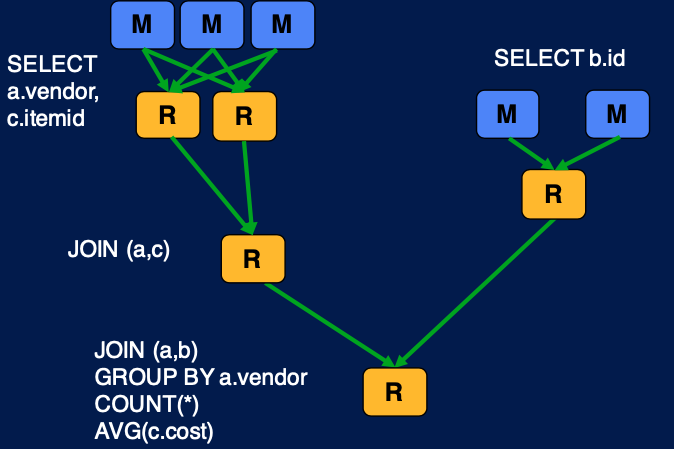
Tez 를 사용하면 조금 더 간단하게 같은 작업을 수행할 수 있다. original map reduce 만을 사용했을 때와의 차이점은 intermediate map task 가 없다는 것이다. map reduce 의 경우 원래는 결과를 hdfs 에 저장하도록 되어있는데, 그러지 않고 데이터를 재사용함으로써 graph 를 간편화할 수 있고 이를 통해 효율적으로 같은 job을 수행할 수 있는 것이다.
Spark 의 경우 advanced DAG execution engine 이며 cyclic data flow 를 지원한다. 또한 in-memory computing 을 지원한다. 우선 데이터 처리를 memory 위에서 할 수 있기 때문에 매우 빠르고, DAG 사이에 데이터 공유도 가능하다는 장점이 있다. 또한 Java, Scala, Python, R 언어를 지원하기 때문에 범용성이 높은 execution engine 이라고할 수 있다. 예를 들어 Spark python interface 를 통해 Logistic regression 을 수행하는 코드를 확인해보자.
points = spark.textFile(...).map(parsePoint).cache()
w = numpy.random.ranf(size = D) # current separating plane
for i in range(ITERATIONS):
gradient = points.map(
lambda p: (1 / (1 + exp(-p.y*(w.dot(p.x)))) - 1) * p.y * p.x
).reduce(lambda a, b: a + b)
w -= gradient
print "Final separating plane: %s" % woriginal map reduce 는 iterative data process 에 적용하기 매우 힘들다는 단점이 있었다. 바로 위 코드에서 iteration 이 등장하는데, 같은 데이터셋을 이용해서 gradient 를 여러번 반복해서 구해서 weight 를 업데이트하는 logistic regression 의 training 과정이다. 우선 같은 데이터셋을 여러번 반복해서 사용하기 때문에 .cache() 함수를 통해 데이터를 RAM 에 저장시킨다. 위 코드는 spark 공식 홈페이지의 예제 (http://spark.apache.org/examples.html)인데 original map reduce 와 100배 정도의 속도차이가 난다고 한다. 이러한 이유로 in-memory computing 이 가능한 경우 선호된다. 이 링크에서는 다양한 Spark 예제를 확인할 수 있다. 또한 spakr 는 Machine learning 을 위한 라이브러리도 제공하기 때문에 이를 직접 구현하지 않고도, high-level interface 를 사용할 수도 있다 (https://spark.apache.org/docs/2.1.0/ml-classification-regression.html).
References
코세라 - Hadoop Platform and Application Framework 강의를 참고하였습니다.
'Data Engineering > Hadoop ecosystem' 카테고리의 다른 글
| 하둡과 응용 프레임워크 3) 하둡 기반 응용 프로그램 (0) | 2020.03.08 |
|---|---|
| Docker 를 통한 Hive 실습환경 구축 및 간단 예제 (0) | 2020.03.02 |
| 하둡과 응용 프레임워크 1) Hadoop Basic module (0) | 2020.02.28 |
| MapReduce 파이썬 구현 - 문서 단어 빈도 세기 (1) | 2020.02.02 |
