Semi-supervised learning 이란?
예를 들어, 우리의 친구 Justine 이 좋아할만한 소설을 예측하고 싶다고 가정하자. 현재 가지고 있는 정보는 "그녀가 최근 읽은 몇 가지 소설" 및 "그 소설들에 대해 그녀가 좋아했는지 안 좋아했는지 여부" 를 알고 있다.
표준적인 supervised machine learning 패러다임에서는 positive example 과 negative example 들의 feature들을 비교하여, 새로운 소설 (unseen) 에 대해 그녀가 좋아할지 안좋아할지를 예측하는 모델을 만든다.
반면, semi-supervied paradigm 은 Justine 이 읽은 소설만 활용하는 것이 아니라 그녀가 읽지 않은 소설 (unlabeled) 까지 활용하여 그녀가 선호할만한 소설을 예측하는 시스템을 만든다. 당연히 전체 소설중, 그녀가 읽지 않은 소설이 훨씬 많을 것이며, 놀랍게도, 이를 활용하면 (unlabeled 데이터를 활용하면) 더욱 효율적인 시스템을 만들 수 있다는 것이다.
Why semi-supervised learning works?


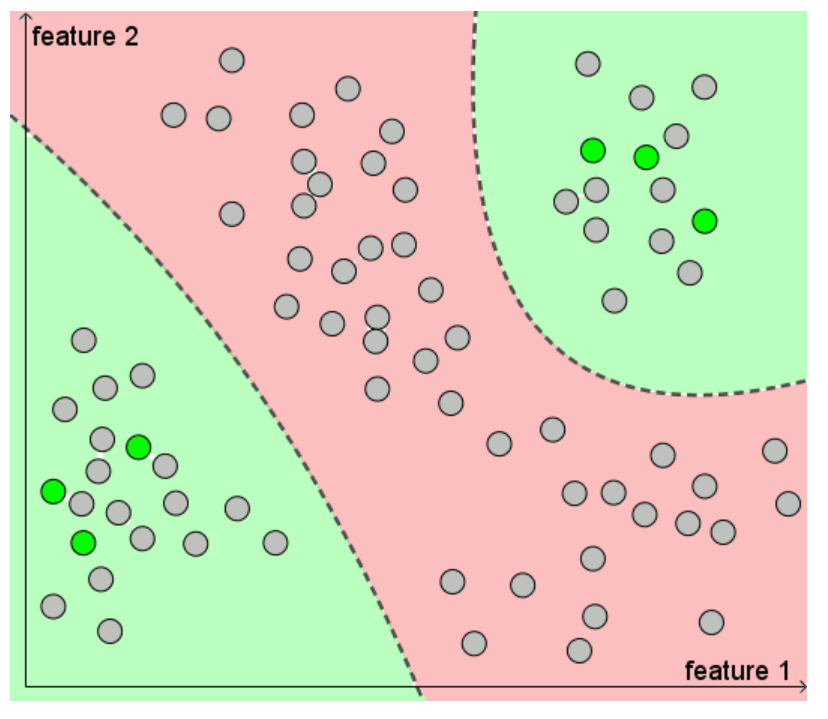
왜 unlabeld 데이터가 예측에 도움이 될 수 있는지를 이해하기 위해 위 그림을 보자.
초록색: positive cases
빨간색: negative cases
선: decision line
unlabeled 데이터를 활용하면 오른쪽 그림처럼 더욱 정교한 decision line 을 그릴 수 있다. 이를 통해 모델의 성능 및 일반화에 도움을 줄 수 있다.
PU learning 의 직관적 이해
Positive-unlabeled learning 은 semi-supervised learning 은 한 가지 패러다임으로, positive case 와 unlabeld case 만 존재하는 문제에서, 사용할 수 있는 방법이다. 위 예시에서 Justine 이 좋아하는 소설에 대한 데이터만 갖고 있는 것이다. real-world 에서 이러한 상황은 생각보다 자주 존재한다. (항상 toy 문제처럼 positive case 와 negative case 가 잘 들어가 있지는 않다.)
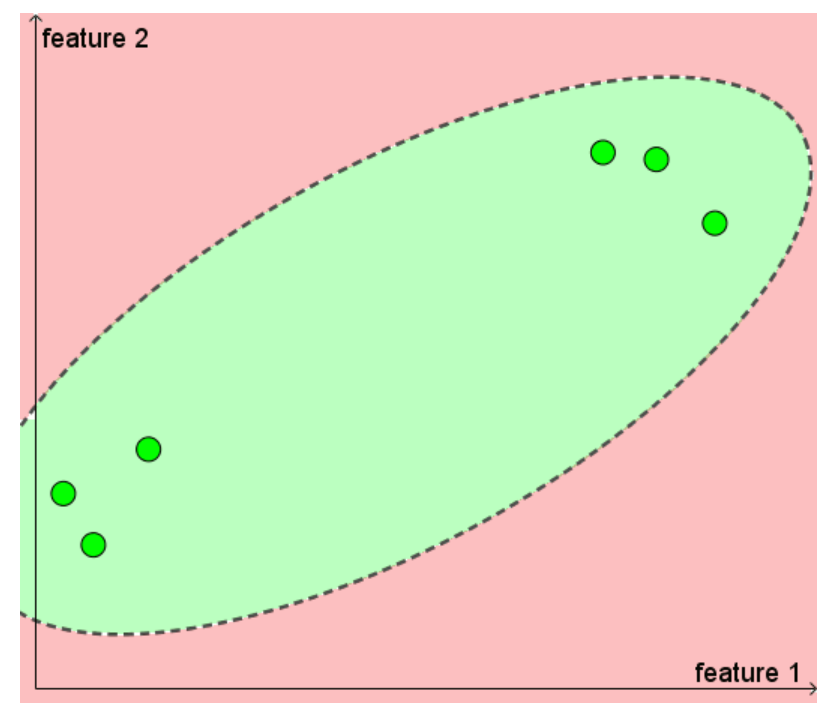
초록색: positive cases
선: decision line
PU learning 이 왜 워킹 하는지에 대해 직관적으로 이해해보자.
1) 왼쪽 그림만을 보고, positive와 negative 를 구분하는 선을 만들라고 하면 어떻게 할 것인가? (머신러닝 모델이 아닌 사람의 직감으로) 다른 데이터들이 어떻게 놓여있는지를 알 수 없기 때문에, 타원 모양의 decision boundary 를 그리는 것이 한 가지 방법이 될 것이다.
2) 오른쪽 그림을 보고, 다시 positive 와 negative 를 구분하는 선을 만들라고 하면 어떻게 할 것인가? 왼쪽 그림과 비교하여 추가적인 정보 (unlabeled 데이터가 어디에 놓여있는지) 를 알고 있다. 그렇기 때문에 그림처럼 다른 decision boundary 를 그릴 수 있게 된다.
PU learning 의 몇 가지 테크닉들
1) Direct application of a standard classifier
가장 기본적인 접근 방법은 unlabeled case 를 negative 로 취급하고 분류 모델을 학습하는 것이다. 이 모델은 각 데이터 포인트에 점수를 주는데, positive case 에 대해서 평균적으로 더 높은 점수를 준다. 만약 unlabeled 데이터 중에 높은 점수를 받은 데이터 포인트가 있다면, positive case 일 확률이 높을 것이다.
이러한 '가장 나이브한 방식' 의 정당성은 이 논문에서 확인되었다 (2008년도). 이 논문의 주요 결과는, 몇 가지 특정한 가정하에, positive+unlabeled 데이터로 학습한 모델의 성능은 positive+negative 데이터로 학습한 결과와 비례한다는것이다.

저자의 코멘트에 따르면, 이 의미는 다음과 같다: "모델이 잘 학습되었다고 가정하면, PU 모델은 어떤 데이터 포인트가 positive 에 속할 가능성에 대한 순위를 매기는데 활용할 수 있다."
2) PU bagging
더욱 정교한 접근 방법은 bagging 의 변형을 활용하는 것이다.
- positive data 와 함께 "unlabeled data 로 부터 random sampling 한 데이터(with replacement)" 를 같이 활용한다.
- 위 boostrap sample 을 negative 로 하여 모델을 학습한다.
- out of bag 샘플 (boostrap sample 에 포함되지 않은 unlabled data) 에 대해 스코어를 매기고, 저장한다.
- 이러한 방법을 반복적으로 적용하고, unlabeled 데이터들에 대해 나온 스코어들을 평균낸다.
이러한 접근 방법이 소개된 논문 (2013년) 에서 저자들은 특히, 갖고 있는 positive sample 숫자가 적고, unlabeled 데이터 중, negative 의 비율이 적은 PU learning 상황에서 state-of-the-art 성능을 달성했다고 주장했다 (2013년도 기준). 또한 unlabeled 데이터의 규모가 큰 경우, 이러한 bagging 방식은 더 빠르게 모델을 학습할 수 있다.
3) Two-step approaches
많은 PU learning 전략은 two-step 접근 방법 카테고리에 속한다. (이 방법이 소개된 논문 (2014년))
Step1 - unlabeled 중에 negative 인 것이 가장 확실한 포인트들을 찾는다. (이를 reliable negative 라고 한다.)
Step2 - positive 와 reliable negative 로 모델을 학습하고, 나머지 unlabeled 데이터에 적용한다.
일반적으로 Step2 의 결과를 통해 Step1 으로 되돌아가서, reliable negative 를 찾고 이를 반복하게 된다. 당연히 reliable negative 의 규모가 충분히 크고, 실제 negative 를 많이 포함하고 있을 수록 더 좋은 모델을 구축할 수 있다. 얼마나 반복해서 적절한 수의 reliable negative 를 찾을 수 있을지가 핵심적인 부분이라고 할 수 있다.
https://roywrightme.wordpress.com/2017/11/16/positive-unlabeled-learning/
Positive-unlabeled learning
A subfield of semi-supervised machine learning, where the only labeled data points available are positive.
roywrightme.wordpress.com
https://github.com/AaronWard/PU-learning-example
GitHub - AaronWard/PU-learning-example: An example repo for how PU Bagging and TSA works.
An example repo for how PU Bagging and TSA works. - GitHub - AaronWard/PU-learning-example: An example repo for how PU Bagging and TSA works.
github.com
'Data science > Machine Learning' 카테고리의 다른 글
| t-SNE 의 개념 및 알고리즘 설명 (1) | 2022.09.11 |
|---|---|
| Semi-supervised learning 의 개념 (0) | 2022.06.13 |
| Scikit-learn Gradient Boosting 모델 예측값이 매번 달라지는 문제와 해결 (0) | 2020.01.30 |
| 구글 번역기의 놀라움 (0) | 2020.01.27 |
| One shot learning, Siamese Network 이해 (1) | 2019.12.31 |
