def myConcat(*cols):
concat_columns = []
for c in cols[:-1]:
concat_columns.append(F.coalesce(c, F.lit("*")))
concat_columns.append(F.lit("\t"))
concat_columns.append(F.coalesce(cols[-1], F.lit("*")))
return F.concat(*concat_columns)
# combined column 에 모든 변수를 \t 로 concat 한 값 저장
data_text = data.withColumn("combined", myConcat(*data.columns)).select("combined")
data_text.coalesce(1).write.format("text").option("header", "false").mode("overwrite").save(path)
근래 빅데이터쪽에서 scalability 라는 개념이 buzzword 중 하나이다. scalability는스케일 아웃에 관한 것이며,스케일 아웃이란 "처리 능력을 향상시키기 위해 트래픽을 분산시킬 서버의 수를 늘리는 방법" 을 의미한다.즉, scalable 머신러닝이란, 머신러닝을 빠르게 처리하기 위해 여러 컴퓨터에 분산시켜 일을 시키는 것으로 정의해볼 수 있다.빅데이터를 어떻게 효율적으로 처리할 것인가? 와 관련한 논의 및 발전이 머신러닝 쪽에서도 이루어지고 있다고 볼 수 있겠다.
3. Missing value handling: Assebling 한 피쳐는 결측이 없어야 함 (NA 가 아닌 0 또는 imputation 된 값이어야 함)
0. Load data
# 데이터 다운로드 받기
# https://www.kaggle.com/datasets/mansoordaku/ckdisease?resource=download
import pyspark
import pandas as pd
from pyspark.sql import SparkSession
from pyspark import SparkContext, SparkConf
import os
import sys
# 환경변수 PYSPARK_PYTHON 와 PYSPARK_DRIVER_PYTHON 의 python path 를 동일하게 맞춰준다.
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
# 환경 세팅
conf_spark = SparkConf().set("spark.driver.host", "127.0.0.1") # local 환경임을 명시적으로 지정해준다.
sc = SparkContext(conf=conf_spark)
# data = pd.read_csv("data/kidney_disease.csv") # pandas 에서 csv 파일 읽기
spark = SparkSession.builder.master("local[1]").appName("kidney_disease").getOrCreate()
data = spark.read.option("header", True).csv("data/kidney_disease.csv") # header가 있는 경우, option 구문 추가
data_pd = pd.read_csv("data/kidney_disease.csv")
1. Preprocessing
#### Imputation : Categorical variable
각 변수별 결측치 개수 확인하기
# 범주형 변수 리스트
cat_cols = ['al', 'su', 'rbc', 'pc', 'pcc', 'ba', 'htn', 'dm', 'cad', 'appet', 'pe', 'ane']
# 각 컬럼별로 결측값 개수를 확인함
# 만약 결측값 코딩이 0으로 되어 있는 경우, filter 조건을 변경하면 된다.
result = pd.DataFrame({'variable':[], 'missing_count':[]})
for col in data.columns:
df_new = pd.DataFrame({'variable':[], 'missing_count':[]})
df_new.at[0, 'variable'] = col
df_new.at[0, 'missing_count'] = data.filter(data[col].isNull()).count()
result = pd.concat([result, df_new], axis=0)
result.astype({'missing_count': 'int32'}) # missing_count 을 int 형으로 변환함
result['missing_rate'] = result['missing_count'] / data.count() # 결측률 계산
result
각 변수별 최빈값 Imputation
from pyspark.sql.functions import when, lit
def mode_of_pyspark_columns(df, cat_col_list, verbose=False):
col_with_mode=[]
for col in cat_col_list:
#Filter null
df = df.filter(df[col].isNull()==False)
#Find unique_values_with_count
unique_classes = df.select(col).distinct().rdd.map(lambda x: x[0]).collect()
unique_values_with_count=[]
for uc in unique_classes:
unique_values_with_count.append([uc, df.filter(df[col]==uc).count()])
#sort unique values w.r.t their count values
sorted_unique_values_with_count= sorted(unique_values_with_count, key = lambda x: x[1], reverse =True)
if (verbose==True): print(col, sorted_unique_values_with_count, " and mode is ", sorted_unique_values_with_count[0][0])
col_with_mode.append([col, sorted_unique_values_with_count[0][0]])
return col_with_mode
col_with_mode = mode_of_pyspark_columns(data, cat_cols)
for col, mode in col_with_mode:
data = data.withColumn(col, when(data[col].isNull()==True,
lit(mode)).otherwise(data[col]))
#### Imputation : Numeric variable
각 변수별 평균값 치환 코드
numeric_cols=['age', 'bp', 'sg','bgr', 'bu', 'sc', 'sod', 'pot', 'hemo', 'pcv', 'rc', 'wc']
from pyspark.sql.functions import avg
from pyspark.sql.functions import when, lit
# 컬럼별 평균값 계산하기
def mean_of_pyspark_columns(df, numeric_cols, verbose=False):
col_with_mean=[]
for col in numeric_cols:
mean_value = df.select(avg(df[col]))
avg_col = mean_value.columns[0]
res = mean_value.rdd.map(lambda row : row[avg_col]).collect()
if (verbose==True): print(mean_value.columns[0], "\t", res[0])
col_with_mean.append([col, res[0]])
return col_with_mean
col_with_mean = mean_of_pyspark_columns(data, numeric_cols)
# with column when 구문으로 null 일 때, 평균으로 치환한다.
for col, mean in col_with_mean:
data = data.withColumn(col, when(data[col].isNull() == True,
lit(mean)).otherwise(data[col]))
2. Categorical variable encoding
범주형 피쳐 인코딩
데이터에 관한 지식을 활용해 모든 피쳐들이 binary 또는 ordinal 변수라는 것을 확인한다. 이 경우, Pyspark 의 StringIndexer 를 활용하여 encoding 해볼 수 있다. 예를 들어, normal/abnormal 의 경우, binary 변수이며, good/poor 등도 각 값들이 독립적이지 않고, 등급이 존재하는 ordinal 변수라는 것을 알 수 있다.
# Categorical 변수들을 StringIndexer 을 이용해 Numeric 변수로 변환함
from pyspark.ml.feature import StringIndexer
indexed = data
for col in cat_cols:
indexer = StringIndexer(inputCol=col, outputCol=col + "Index")
indexed = indexer.fit(indexed).transform(indexed)
예를 들어, 아래와 같이 새로운 컬럼이 생성된다.
# 각 범주형 변수별로 Index 변수를 아래와 같이 만든다.
indexed.select(['id', 'pc', 'pcIndex']).show()
# 잘못된 값이 있기 때문에 이를 replace 해준다.
indexed = indexed.withColumn("classification", \
when(indexed["classification"] == 'ckd\t', 'ckd').otherwise(indexed["classification"]))
결과를 보면, notckd 를 1, ckd를 0으로 인코딩 해주었는데, 반대로 notckd를 0, ckd를 1로 바꾸어 인코딩해보자.
- Numeric 변수들을 Double 형으로 변환한다. - 이 때 주의할점은, 만약 원래 numeric 변수인데, 오류로 인해 문자가 들어있는 경우, Double 형변환을 하면 값이 null 이 된다. - 따라서 확인하고, imputation 을 한 번 더 수행해야할 수도 있다.
numeric 변수들을 double 형으로 변환하기
from pyspark.sql.types import DoubleType
for col in numeric_cols:
indexed = indexed.withColumn(col, indexed[col].cast(DoubleType()))
# with column when 구문으로 null 일 때, 평균으로 치환한다.
for col, mean in col_with_mean:
indexed = indexed.withColumn(col, when(indexed[col].isNull() == True,
lit(mean)).otherwise(indexed[col]))
3. Assembling of Input Features
- feature 를 assemble 하여 하나의 필드로 변환 후, 이후 피쳐 변환이나 모델링 절차 등이 수행한다.
피쳐들의 Type 재확인
-> 모두 double type 이라는 것을 알 수 있음
for col in indexed[feature_list].dtypes:
print(col[0]+" , "+col[1])
VectorAssemble 활용
피쳐들을 assemble 한 features 라고 하는 컬럼을 생성한다. inputCols 파라미터에 피쳐명을 리스트 형태로 지정하고, outputCols 에 assemble 한 값을 넣을 컬럼명을 넣는다.
# 주의 사항: Assemble 을 할 때, 데이터에 결측이 없어야함
from pyspark.ml.feature import VectorAssembler
vectorAssembler = VectorAssembler(inputCols=feature_list,
outputCol="features")
features_vectorized = vectorAssembler.transform(indexed)
변수의 scale 이 모델 성능에 미치는 영향을 줄여줌. 피쳐들의 스케일까지 학습해야 하는 부담을 줄일 수 있다.
ㄴ 만약 normalization 이 적절히 수행된다면, 단점은 없고 장점만 있기 때문에 일반적으로 많이 수행한다.
Normalizer 를 활용한 standard scaling
inputCols 로 assemble 한 컬럼을 넣어주고, outputCols 로 normalization 된 피쳐를 넣을 컬럼명을 지정해준다. p는 normalization 을 할 때, L1 norm 을 이용하는 것을 의미한다. (default 는 L2 norm 이다.) 본 포스팅에서 normalization 수식이나 변환 결과는 생략한다.
#Split the dataset into training and testing dataset
splits = preprocessed_data.randomSplit([0.8, 0.2])
df_train = splits[0]
df_test = splits[1]
6. Train & Predict
pyspark 에서 학습하고 예측하는 일에 대해 fit, transform 이라는 용어를 사용한다. fit 은 학습 데이터를 입력 받아 모델을 만드는 작업업을 의미하며, transform 은 예측하고 싶은 데이터를 입력 받아, 학습된 모델로 그 데이터의 label을 예측한다.
from pyspark.ml.classification import RandomForestClassifier
# Train a RandomForest model.
rf = RandomForestClassifier(labelCol="label", featuresCol="features_norm", numTrees=10)
rf_model = rf.fit(df_train)
prediction = rf_model.transform(df_train)
transform 을 수행하면, rawPrediction, probability, prediction 이라는 컬럼을 데이터에 추가해준다.
- rawPrediction (list): random forest 의 각 tree 들이 각 클래스에 속한다고 예측한 값들의 합이다.
- probabilty (list): rawPrediction 을 0~1 사이로 scaling 한 값
- prediction (element): probabilty 를 토대로 가장 가능성이 높은 label 예측한 값
t-SNE (t-distributed Stochastic Neighbor Embedding) 는 고차원 데이터를 저차원 데이터로 변환하는 차원 축소 (dimensionality reduction) 기법이며, 대표적이며, 좋은 성능을 보이는 기법이다.
차원 축소을 하는 목적은 시각화, 클러스터링, 예측 모델의 일반화 성능 향상 등의 목적을 들 수 있다. t-SNE 의 경우, 고차원 공간상의 데이터 포인트들의 위치를 저차원 공간상에서의 극적으로 표현을 해주기 때문에 데이터에 존재할 수 있는 군집들을 시각화해서 표현해주는데 강점을 갖고, 시각화에 주로 사용된다. t-SNE 는 직접적으로 클러스터를 만들어서 레이블링까지 해주는 클러스터링 알고리즘은 아니다. 따라서 클러스터링에 직접적으로 활용되기 보다는 t-SNE 의 결과에 다시 k-means 와 같은 알고리즘을 적용하는 방식으로 클러스터링을 수행하기도 한다 (참고: https://www.quora.com/Can-TSNE-be-used-for-clustering). t-SNE 는 PCA 와 같이 저차원에서 요약된 변수에 의미가 있는 것은 아니다. (PCA 의 경우, 저차원 공간의 변수가 고차원 공간상의 변수들의 선형 결합이라는 의미가 있다.)
차원 축소의 3가지 카테고리
1) feature selection: univariate association test, ensemble feature selection, step-wise regression 등
3) neighbor graphs: t-sne, UMAP (Uniform Manifold Approximation and Projection) 등
우선, t-sne 는 비선형 차원 축소 (nonlinear dimensionality reduction) 기법이다. 따라서 아래와 같은 데이터에 대해서도 적용할 수 있다. 반면 PCA (principle component analysis) 와 같은 선형 차원 축소 방법의 경우 아래 데이터에 적용하여 유의미한 결과를 내기는 어렵다.
선형 차원 축소 기법으로 차원 축소가 어려운 형태의 데이터
t-SNE 알고리즘
sne, t-sne, UMAP 과 같은 차원 축소 방법은 아래의 공통된 절차를 수행한다.
원래 데이터가 있는 공간을 high dimension, 축소된 공간을 low dimension 이라고 하자.
1) high dimensional probabilities p 를 계산한다. 2) low dimensional probabilities q 를 계산한다. 3) 두 분포의 차이를 반영하는 cos function C(p,q) 를 정의한다. 4) Cost function 이 최소화 되도록 저차원 공간상의 데이터를 변환한다.
대략적인 절차는 매우 심플하다. t-sne 에서는 각 절차를 실제로 어떻게 수행하는지 알아보자.
1) high dimensional probabilities p 를 계산한다.
p_(i,j) 를 어떤 데이터 포인트 i,j의 similarity 를 반영하는 스코어라고 하자. 두 포인트가 가까이 위치할 수록 p_(i,j) 의 값은 커지게 된다. 그리고 i,j 의 euclidean distance 를 e_(i,j) 라고 하자. 다른 데이터들에 대해서도 서로의 eucliean distance 를 계산할 수가 있고, 그 값들이 어떤 분포 g 를 따른다고 가정하자. p_(i,j) 는 그 분포상에서의 likelihood 라고 할 수 있는, g(e(i,j)) 로 정의해보자.
예를 들어 설명하면, 위 두 데이터 포인트를 각각 (2,9) 와 (3,10) 이라고 하자. e= sqrt((3-2)^2 + (10-9)^2)=sqrt(2) = 1.41 이다.
그러면, p(j|i) 의 값이 p(i|j) 의 값은 다른데, 최종적으로 두 값의 평균을 취하고, 마찬가지로 모든 값의 합이 1이 되도록 하기 위하여 최종적인 i,j 의 similarity score p(i,j) 를 아래와 같이 계산한다 (N은 계산 가능한 쌍의 수). 이러면, p 를 이산확률분포처럼 다룰 수 있게 된다.
이를 위해하기 위해 우선, entropy 와 perplexity 라는 개념에 대한 설명이 필요하다. perplexity = 2^entropy 로 정의되며, entropy 는 '어떠한 확률 분포에 대하여, 관측값을 예측하기 어려운 정도' 를 의미하는 수치이다. 어떤 분포 q 에대한 entropy 는 아래와 같다.
$$ H(q) = -\sum_{c=1}^{C} q(y_c)log(q(y_c)) $$
entropy 를 설명하기 위해, 빨간공과 녹색공이 20:80 으로 들어 있는 가방에서 1개의 공을 꺼내서 관찰 값을 확인하는 이산 확률 분포를 예로 들어보자. 그 확률 분포 q의 entropy 는 H(q)=-(0.2log(0.2)+0.8log(0.8))=0.5 이다. 그리고, perplexity = 2^0.5 = 1.41 이다.
perplexity 값에 따라 t-SNE 의 결과가 민감하게 반응하기 때문에 perplexity 는 중요한 파라미터이다. 보통 t-SNE 는 입력받은 perplexity 를 맞추는 σ 를 찾기 위하여 binary search 를 수행한다. 일반적으로 perplexity 를 조정하면서 시각화를 해보고, 가장 군집을 잘 보여주는 값을 최종적으로 선정하는 방법을 택한다.
왜 p, q 분포는 위와 같이 정해지는가?
p분포는 정규 분포와 유사하며, q분포는 t분포와 유사한 형태를 띈다. q 분포의 경우, p 분포 대비 빠르게 하락하고, 꼬리가 두터운 형태의 분포를 갖는다. q분포를 썼을 때의 효과는 한 점에 데이터가 뭉치는 crowding problem 을 완화시킨다는데 있다. 따라서, 시각화시 저차원 공간상에서 너무 한 점에 뭉치지 않도록 하는 효과가 있기 때문에 p 분포를 썼을 때보다 이점이 있다. (이는 개인적인 이해를 위한 해석이며, 이와 관련한 좀 더 디테일한 설명은 original paper 를 참고)
구현 레벨에서의 최적화
t-SNE 는 데이터가 커질수록 연산량이 기하급수적으로 늘어나는 O(n^2) 의 시간 복잡도를 갖는다. 실제 구현 레벨에서는 Barnes hut t-SNE 라는 방법을 통해 더 계산 효율적인 구현 방식을 택한다. scikit-learn 의 t-sne 구현체는 이 방식을 활용한다.
t-SNE 의 optimization
t-SNE 에서의 optimization 이란 고차원 공간상에서의 p분포 (high dimensional probabilities p) 와 저차원 공간상의 q분포 (low dimensional probabilities q ) 의 차이를 줄이는 것이다. 이 때, cost function 을 정의하고, 이를 최소화하는 방식으로 optimization 이 수행된다.
3) 두 분포의 차이를 반영하는 cos function C(p,q) 를 정의한다.
cost function C(p,q) 로는 Kullback-Leibler divergence 를 사용한다. p,q는 이산확률분포이고, KL divergence의 식에 적용하면 cost 를 실제로 구해볼 수도 있다.
4) Cost function 이 최소화 되도록 저차원 공간상의 데이터를 변환한다.
KL divergence 을 최소화 시키는 저차원 공간상의 데이터의 위치를 gradient optimization 방식을 통해 구할 수 있다. 설명하자면, 결국 저차원 공간상에 랜덤하게 뿌려진 데이터 포인트들이 각각 어떤 방향으로 가야지 cost function 을 줄일 수 있을지 알아야 하는 것인데, 이는 cost function 을 미분한 뒤에 각 데이터 포인트 별로 gradient 를 구함으로써 알 수 있다.
데이터 처리 중, 각 컬럼별로 동일한 함수를 적용시키고 싶을 때가 있다. 예를 들면, string 형태로 저장된 컬럼들을 일괄적으로 numeric으로 바꾸고 싶다고 하자. 이 때, lapply 를 유용하게 사용할 수 있다.
정보) lapply 는 vector, list 를 인풋으로 받아 list 를 아웃풋으로 내보낸다.
아래 함수는 vars 에 지정된 컬럼들을 lapply 함수를 활용해 일괄적으로 numeric 형으로 변환하는 코드이다.
# vars 에 numeric 으로 변환하고 싶은 컬럼
data[,vars] <- lapply(vars, function(x){
as.numeric(unlist(data[,x])) # [,x] 방식의 컬럼 선택은 output 을 list 형태로 반환한다.
})
위 코드를 설명하면 우선 각 컬럼 x 별로 as.numeric 함수를 적용시켜 이 값을 list of vectors 로 반환한다. 그리고 이 반환값이 dataframe 의 컬럼값을 지정하도록 수행된다. (이러한 코드가 가능한 이유는 dataframe 이 기본적으로 list 의 결합이기 때문이다.)
최초로 데이터를 받은 이후에, 가장 먼저할 작업은 탐색적 데이터 분석이다. 탐색적 데이터 분석을 통해 각 변수별로 처리 방법을 계획하여, 분석하기 쉬운 형태의 데이터로 만들게 된다. 이 과정에서 변수의 변환, 제거, 생성, 결측값 처리 등의 절차를 수행하게 된다. 본 포스팅은 pyspark 를 통해 데이터를 탐색적으로 확인하는 방법과 간단한 데이터 처리 방법 몇 가지를 다룬다.
pyspark 를 통한 탐색적 분석 문법은 pandas 와 유사한 부분도 있고, 그렇지 않은 부분도 있다. 자주 등장하는 pyspark 의 특이적인 문법이 존재하는데, R, pandas 만 활용해온 사람이라면 이러한 부분에 점점 익숙해질 필요가 있을 것 같다.
# 데이터 다운로드 받기
# https://www.kaggle.com/datasets/mansoordaku/ckdisease?resource=download
import pyspark
import pandas as pd
from pyspark.sql import SparkSession
from pyspark import SparkContext, SparkConf
import os
import sys
# 환경변수 PYSPARK_PYTHON 와 PYSPARK_DRIVER_PYTHON 의 python path 를 동일하게 맞춰준다.
os.environ['PYSPARK_PYTHON'] = sys.executable
os.environ['PYSPARK_DRIVER_PYTHON'] = sys.executable
# 환경 세팅
conf_spark = SparkConf().set("spark.driver.host", "127.0.0.1") # local 환경임을 명시적으로 지정해준다.
sc = SparkContext(conf=conf_spark)
0. 데이터 로드
pyspark 에서 csv 파일을 load 하는 것은 아래 문법으로 수행할 수 있다.
# data = pd.read_csv("data/kidney_disease.csv") # pandas 에서 csv 파일 읽기
spark = SparkSession.builder.master("local[1]").appName("kidney_disease").getOrCreate()
data = spark.read.option("header", True).csv("data/kidney_disease.csv") # header가 있는 경우, option 구문 추가
data_pd = pd.read_csv("data/kidney_disease.csv")
1. Schema: 데이터 스키마 확인하기
어떤 구조와 변수형으로 데이터가 들어가 있는지 먼저 파악한다.
- 데이터를 직접 추출하여 만들었다면, 각 컬럼이 무엇을 의미하는지 알겠지만.. - 연습을 위한 토이 데이터이거나, 다른 사람한테 받은 데이터라면, 각 컬럼이 무엇을 의미하는지 이해하고 넘어갈 필요가 있다.
우선 연속형 변수를 double 형으로 변환해준다. 여기서도 withColumn 구문을 활용할 수 있다.
# 연속형 변수들은 double 로 형변환 수행
numeric_cols = ['age', 'bp', 'sg', 'al', 'su', 'bgr', 'bu', 'sc', 'sod', 'hemo', 'pcv', 'wc', 'rc']
for c in numeric_cols:
data = data.withColumn(c, data[c].cast('double'))
위 결과를 pandas dataframe 으로 변환하고, transpose 를 시켜 보기 쉬운 데이터 형태로 변환한다.
# 첫번째 로우를 header 로 변경
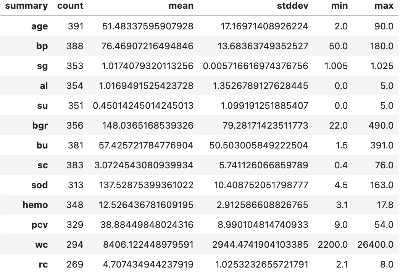
numeric_dist = data.describe(numeric_cols).toPandas().T
new_header = numeric_dist.iloc[0] #grab the first row for the header
numeric_dist = numeric_dist[1:] #take the data less the header row
numeric_dist.columns = new_header #set the header row as the df header
# 인덱스컬럼의 값을 추출해서 새로운 컬럼으로 지정
numeric_dist['col'] = numeric_dist.index.values
numeric_dist.reset_index(drop=True, inplace=True)
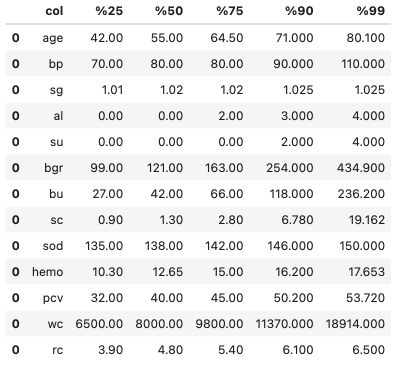
#### agg 함수 사용: quantile 값 추출
- 아래와 같이 agg 함수를 활용해 연속형 변수의 quantile 값을 추출할 수 있다.
- pyspark.sql.functions 의 expr 함수를 활용해, agg 함수 내에 원하는 집계 방법을 string 형태로 넣어서 quantile 을 구할 수 있다.
import pyspark.sql.functions as F
perc = pd.DataFrame({'col':[], '%25':[], '%50':[], '%75':[], '%90':[], '%99':[]})
for c in numeric_cols :
result_new = data.agg(
F.expr('percentile(' + c + ',array(0.25))')[0].alias('%25'),
F.expr('percentile(' + c + ',array(0.50))')[0].alias('%50'),
F.expr('percentile(' + c + ',array(0.75))')[0].alias('%75'),
F.expr('percentile(' + c + ',array(0.90))')[0].alias('%90'),
F.expr('percentile(' + c + ',array(0.99))')[0].alias('%99'),
).toPandas()
result_new['col'] = c
perc = pd.concat([perc, result_new], axis=0)
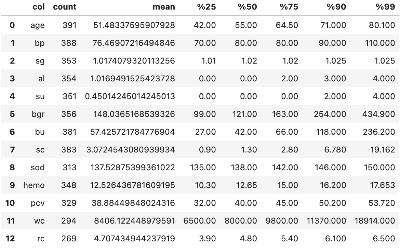
#### 두 결과 테이블 조인하기
- 위 두 테이블을 조인하여 최종적으로 원하는 형태의 연속형 변수 분포 테이블을 만들어 볼 수 있다.
5. Distribution: 단변수 분포 확인하기 - Categorical variable
#### 범주형 변수에서 unique 한 값 추출하기
- 아래 스크립트에서 rdd.map 이 pyspark 특이적인 문법이라고 볼 수 있다.
ㄴ rdd 는 dataframe 을 rdd 형태로 다룰 것임을 의미하며, rdd 에 lambda 함수를 적용해 결과를 추출한다.
ㄴ collect 함수는 결과를 list 형태로 만들어준다.
ㄴ 이러한 문법은 pandas 나 R 에서는 잘 나오지 않기 때문에 익숙해질 필요가 있을 것 같다.
from pyspark.sql.functions import when
from pyspark.sql import functions as F
# Label 변수 확인하기
print(f"labels: {data.select('classification').distinct().rdd.map(lambda r: r[0]).collect()}")
# data_pd['classification'].unique() # pandas 의 경우는 이와 같이 한다.
labels: ['notckd', 'ckd', 'ckd\t']
#### 분포 확인하기
- sql.function 내 agg 함수 내에 원하는 집계 (count) 함수를 넣어, 아래와 같이 그룹별 행수를 계산할 수 있다.
result = data.select(['classification']).\
groupBy('classification').\
agg(F.count('classification').alias('user_count')).toPandas()
result
6. Drop useless columns: 컬럼 드랍하기 (Option)
- 필요 없는 컬럼이 있는 경우 drop 함수로 드랍한다.
data = data.drop('pot')
print(f"Row count: {data.count()}")
print(f"Column count: {len(data.columns)}")
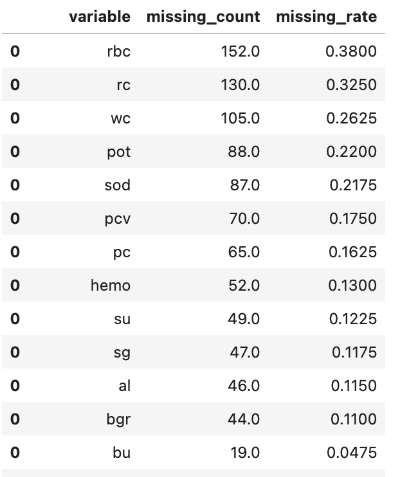
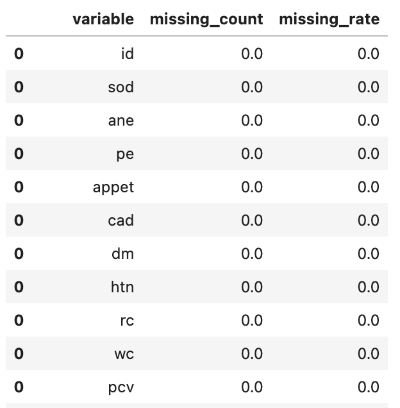
- 컬럼별로 결측값 개수를 구하는 것은 다양한 방식으로 구현할 수 있지만, 가장 간단하게 for 을 활용하는 방법은 아래와 같다.
# 각 컬럼별로 결측값 개수를 확인함
# 만약 결측값 코딩이 0으로 되어 있는 경우, filter 조건을 변경하면 된다.
result = pd.DataFrame({'variable':[], 'missing_count':[]})
for col in data.columns:
df_new = pd.DataFrame({'variable':[], 'missing_count':[]})
df_new.at[0, 'variable'] = col
df_new.at[0, 'missing_count'] = data.filter(data[col].isNull()).count()
result = pd.concat([result, df_new], axis=0)
result.astype({'missing_count': 'int32'}) # missing_count 을 int 형으로 변환함
result['missing_rate'] = result['missing_count'] / data.count() # 결측률 계산
# 결측률이 높은 순서대로 출력한다.
# rbc 컬럼의 결측율이 38% 로 가장 높은 것을 확인할 수 있다.
result.sort_values(by=['missing_rate'], ascending=False)
9. Replace: 값 치환하기
- 데이터를 다루다보면 종종 값을 치환해야할 경우가 있다. (값이 잘못 들어가 있는 경우, 카테고리를 합치는 경우 등..)
- withColumn 구문과 when 구문을 합쳐여 값 치환을 구현해볼 수 있다.
# label 에 'ckd\t' 로 데이터가 잘못 들어가 있는 것을 확인할 수 있다.
# 이를 when 구문을 통해 원하는 값으로 바꾸어준다.
data = data.withColumn("classification", \
when(data["classification"] == 'ckd\t', 'ckd').otherwise(data["classification"]))
# 재출력하기
print(f"처리후 labels: {data.select('classification').distinct().rdd.map(lambda r: r[0]).collect()}")
처리후 labels: ['notckd', 'ckd']
10. Imputation: 평균대치법 (for numeric variable)
- 본 데이터셋은 결측값이 null 로 채워져 있다. 평균 대치법으로 결측값을 처리하자.
- 먼저, 특정 컬럼의 평균을 구하는 함수를 작성한다.
ㄴ pyspark 에서는 이와 관련한 readymade 함수가 없기 때문에 직접 작성한다.
- 여기서도 df.select(avg(df[col]))) 이나 rdd.map 같은 pyspark 특이적 문법이 등장한다.
from pyspark.sql.functions import avg
from pyspark.sql.functions import when, lit
# 컬럼별 평균값 계산하기
def mean_of_pyspark_columns(df, numeric_cols, verbose=False):
col_with_mean=[]
for col in numeric_cols:
mean_value = df.select(avg(df[col]))
avg_col = mean_value.columns[0]
res = mean_value.rdd.map(lambda row : row[avg_col]).collect()
if (verbose==True): print(mean_value.columns[0], "\t", res[0])
col_with_mean.append([col, res[0]])
return col_with_mean
# with column when 구문으로 null 일 때, 평균으로 치환한다.
for col, mean in col_with_mean:
data = data.withColumn(col, when(data[col].isNull() == True,
lit(mean)).otherwise(data[col]))
for col, mode in col_with_mode:
data = data.withColumn(col, when(data[col].isNull()==True,
lit(mode)).otherwise(data[col]))
결측값 치환이 잘 되었는지를 확인한다. 결측값이 없는 데이터가 되었음을 확인할 수 있다.
# 각 컬럼별로 결측값 개수를 확인함
# 만약 결측값 코딩이 0으로 되어 있는 경우, filter 조건을 변경하면 된다.
result = pd.DataFrame({'variable':[], 'missing_count':[]})
for col in data.columns:
df_new = pd.DataFrame({'variable':[], 'missing_count':[]})
df_new.at[0, 'variable'] = col
df_new.at[0, 'missing_count'] = data.filter(data[col].isNull()).count()
result = pd.concat([result, df_new], axis=0)
result.astype({'missing_count': 'int32'}) # missing_count 을 int 형으로 변환함
result['missing_rate'] = result['missing_count'] / data.count() # 결측률 계산
# 결측률이 높은 순서대로 출력한다.
# rbc 컬럼의 결측율이 38% 로 가장 높은 것을 확인할 수 있다.
result.sort_values(by=['missing_rate'], ascending=False)
한 마디로 빅데이터 환경에서 전통적인 데이터 처리 툴들 (R, pandas) 을 활용하기 어렵기 때문이다. 토이 데이터의 경우, 10GB 를 넘는 경우가 드물지만, 실제 회사의 빅데이터 환경에서는 하나의 데이터셋이 10GB 를 넘는 경우가 많으며, 크게는 10TB를 넘는 경우도 있다. 기본적으로 R과 python pandas 는 in-memory 처리 방식이다. 모든 데이터를 메모리에 적재한 후, 처리한다. 만약 램이 8GB 인 머신을 사용한다고 하면, 이러한 데이터들을 로드조차 하지 못하고, out-of-memory 에러로 커널이 죽는 모습을 확인할 수 있게 된다.
pyspark 환경에서는메모리 사용량을 최소화하는 방식으로 용량이 크고, 포맷이 다양한 데이터들을 "특정 데이터 구조" 로 로드하고 처리하는 것이 가능하다. 즉, pyspark 는 시간 및 컴퓨팅 자원 측면에서 효율적으로 데이터 처리/분석을 할 수 있도록 도와준다.
만약, 데이터 분석 공부를 하거나, 큰 데이터를 접할 일이 없는 도메인에서 일을 하는 경우에는 R 또는 pandas 만 사용하여도 괜찮다. 하지만 빅데이터 환경에서 데이터를 처리하고 분석하는 것이 필요하다면, pyspark 를 활용하는 것이 더욱 효율적이며, 이것이 pyspark 를 배우면 좋은 이유이다.
pyspark 의 핵심 데이터 타입은 dataframe 이다. pyspark dataframe 은 쉽게 말해 여러 클러스터에 분산 되어 있는 테이블이라고 할 수 있다. 그 이름처럼 R이나 pandas의 dataframe 과 비슷한 함수들을 갖고 있다. 분산 실행을 위해서는 다른 데이터 타입이 아닌 pyspark 의 dataframe 객체를 이용하면 된다. pyspark dataframe을 활용하는 것은 R 과 pandas 와 거의 비슷하기 때문에, 둘 중 하나에 익숙한 경우 쉽게 활용할 수 있다.
pyspark 와 pandas 의 큰 차이점 중 하나는 pyspark 는 lazy 하고, pandas 는 eager 하다는 것이다. pyspark 에서는 실제 결과가 필요할 때까지 실행을 유보한다 (lazy evaluation). 예를 들어, hive 환경에 있는 테이블을 읽어온 후, 특정 변수를 변환하는 코드를 짰다고 하자. 하지만 이 코드를 실행하는 즉시, 이 작업이 실행되지 않는다. 실제 데이터가 필요한 경우에만 이 작업이 실행횐다 예를 들어, 변환된 테이블을 다시 hive 환경에 파일로 저장하는 등의 경우를 들 수 있다. 이러한 방식이 좋은 점은 전체 데이터를 메모리에 저장하지 않아도 되기 때문에, 효율적으로 데이터를 처리할 수 있다. 반면, pandas 에서는 함수가 호출되는 즉시 실행되며 (eager evaluation), 모든 것은 메모리에 저장된다. pyspark 환경에서의 데이터 처리를 한다고 했을 때, eager operation 은 사용하는 것은 지양하는 것이, 리소스 절감 측면에서 바람직하다고 할 수 있다.