실무를 하다보면 롱테일 분포를 많이 접하게 됩니다. 예를 들어서, 어떠한 이커머스 서비스에서 "구매 금액" 이라는 변수를 살펴보면, 대부분의 유저는 구매금액이 0~1만원 사이에 들어있지만, 일부 유저는 구매금액이 몇 백만원 심지어는 몇 억원에 이르는 경우를 심심찮게 볼 수 있습니다. 극심한 right-skewed 분포 (또는 롱테일 분포)의 예라고 볼 수 있습니다.
이러한 롱테일 분포에 일반적인 히스토그램을 적용하게 되면 꼬리가 너무 길어져 가시성이 좋지 않습니다. 이런 경우에 특정 cutff 지점을 정해 따로 범주를 만들곤 합니다. 예를 들어, 구매금액이 백만원 이상인 유저는 '100만원 이상' 이라는 bucket 을 따로 만드는 것이죠. 꼬리 부분이 너무 길기 때문에 이 부분을 따로 모으는 것입니다.
R 코드로는 다음과 같이 작성해볼 수 있습니다. 포인트는 raw 데이터에 적용하는 geom_hist 를 사용하는 것이 아니라, 집계 데이터를 먼저 만든 후, geom_bar 를 통해 히스토그램을 그리는 것입니다. 그리고, 집계 데이터를 만들기 위해 cut 함수를 사용합니다.
R 코드
anal_table 데이터 프레임의 value 컬럼이 histogram 을 그리고자하는 변수입니다.
top_1_percent <- quantile(anal_table$value, 0.99, na.rm=T) # 상위 1% 경계값 찾기
# bucket size 동적으로 설정
bucket_size <- 10^ceiling(log10(top_1_percent)) # 초기 bucket size
# while loop를 통해 bucket size 조정
while(TRUE) {
breaks <- seq(0, top_1_percent, by = bucket_size) # 상위 1% 까지의 bucket
if(length(breaks) > 100) break # bucket 개수가 100개 이상이면 loop 탈출
bucket_size <- bucket_size / 10 # bucket size 재조정
}
labels <- breaks
cutoff <- max(labels)+bucket_size
# 기본적으로 break 에서 좌측을 포함하지 않고 우측을 포함함(include lowest 를 통해 가장 좌측은 포함)
# right=FALSE 를 통해 우측을 포함하지 않게 지정
anal_table$bucket <- cut(anal_table$value, breaks = seq(0, cutoff, by = bucket_size),
include.lowest = TRUE,
right=FALSE,
labels = labels)
# bucket 이 없는 경우는, cutoff 이상인 경우로, 따로 만든 bucket 에 속하도록 바꾸어줌
anal_table <- anal_table %>% mutate(bucket = if_else(is.na(bucket), as.character(ceiling(cutoff)), bucket))
anal_table$bucket <- factor(anal_table$bucket, levels = c(labels, ceiling(cutoff)))
summary_data <- anal_table %>% group_by(bucket) %>% count()
summary_data
summary_data <- summary_data %>% mutate(var_name = var_name)
val_quantile <- quantile((anal_table %>% select(value) %>% pull), probs=seq(0.1, 1, 0.1))
quantile_keys <- names(val_quantile)
quantile_values <- unname(val_quantile)
df_quantile <- data.frame(t(quantile_values))
colnames(df_quantile) <- quantile_keys
df_avg <- anal_table %>% summarize(avg = mean(value))
df_quantile <- cbind(df_quantile, df_avg)
df_quantile <- df_quantile %>% mutate(var_name = var_name)
total_ticks <- 10
breaks <- pretty_breaks(n = total_ticks)(range(as.numeric(as.character(summary_data$bucket))))
ggplot(summary_data, aes(x = as.numeric(as.character(bucket)), y = n)) +
scale_y_continuous(labels = scales::label_comma()) +
geom_bar(stat = "identity", fill = "black") +
labs(x = "X", y = "Y") +
scale_x_continuous(breaks = breaks, # breaks는 pretty_breaks를 사용해 계산된 값
labels = breaks) + # labels도 breaks를 사용
theme_bw(base_size = 10, base_family = "Kakao Regular") +
ggtitle("Histogram from Binned Data") +
theme(plot.margin = margin(0.5, 0.5, 0.5, 0.5, "cm")) +
geom_vline(aes(xintercept = df_quantile$avg), colour = "red") +
annotate("text", x = df_quantile$avg, y = max(summary_data$n),
label = paste("평균 =", round(df_quantile$avg, 2)),
vjust = 2, color = "black", size=3)
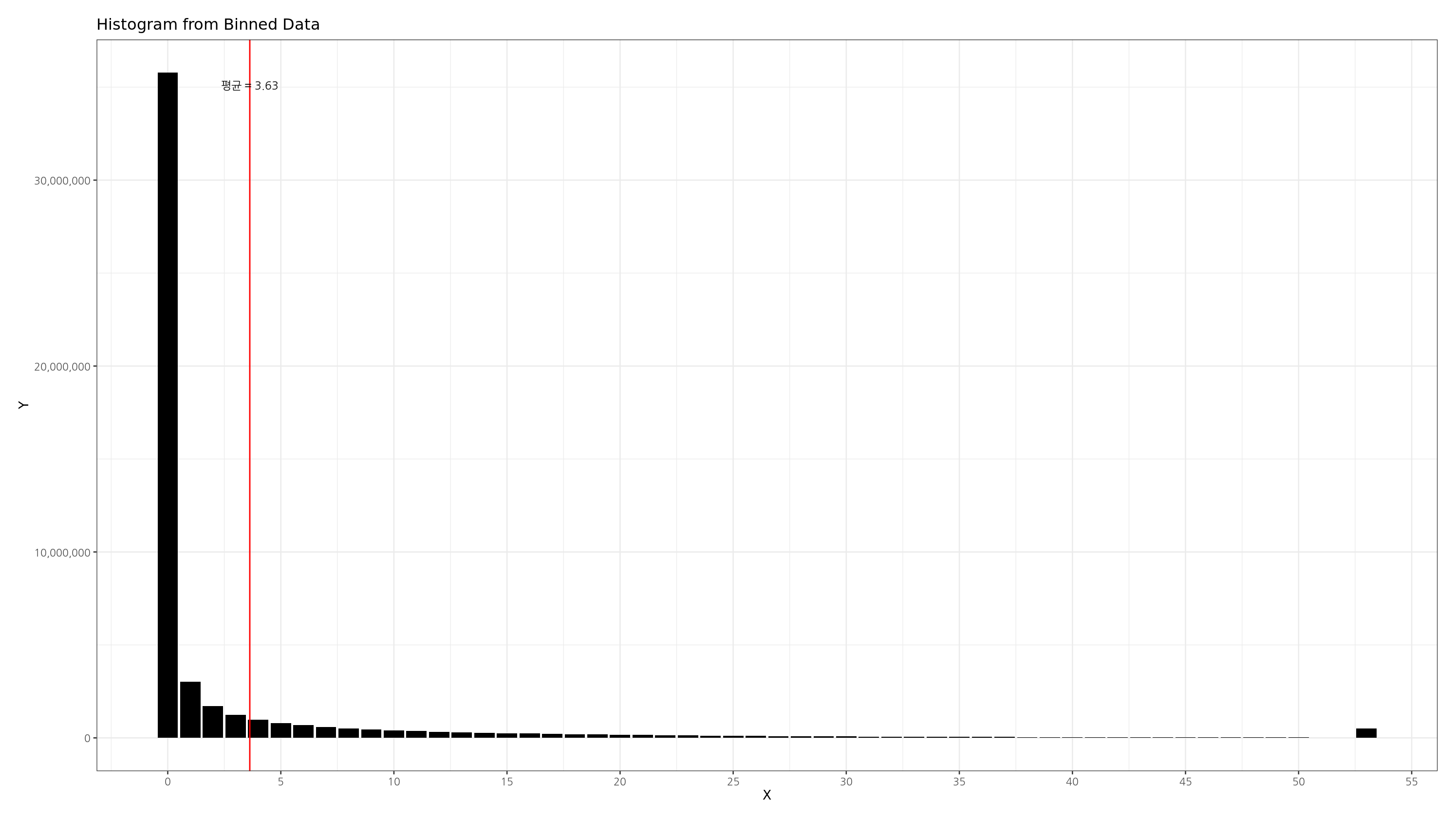
결과 히스토그램
위 코드를 통해 아래와 같이 지정된 bucket size 를 가지며, 상위 1% 이상은 하나의 bucket 으로 묶은 깔끔한 히스토그램을 그릴 수 있습니다.
위 코드에는 몇 가지 포인트가 있습니다. bucket size(bin)과 xtick 의 개수를 동적으로 결정한 부분인데요. 이 부분 코드를 좀 더 살펴보겠습니다.
bucket size 를 동적으로 결정하기
bucket 의 개수가 최소 100개가 되도록 하며, bucket size 가 1, 10, 100, 1000 처럼 10의 지수형태로 만드는 방법은 아래와 같습니다.
또한 cut 함수의 labels 를 통해 label 을 이쁘게 만들어줍니다. 예를 들어 label 이 100이라고 하면, (100~199 사이의 bucket 을 의미하는 등)
# while loop를 통해 bucket size 조정
while(TRUE) {
breaks <- seq(0, top_1_percent, by = bucket_size) # 상위 1% 까지의 bucket
if(length(breaks) > 100) break # bucket 개수가 100개 이상이면 loop 탈출
bucket_size <- bucket_size / 10 # bucket size 재조정
}
labels <- breaks
cutoff <- max(labels)+bucket_size
# 기본적으로 break 에서 좌측을 포함하지 않고 우측을 포함함(include lowest 를 통해 가장 좌측은 포함)
# right=FALSE 를 통해 우측을 포함하지 않게 지정
anal_table$bucket <- cut(anal_table$value, breaks = seq(0, cutoff, by = bucket_size),
include.lowest = TRUE,
right=FALSE,
labels = labels)
동적 xtick 의 결정
아래 코드는 총 xtick 의 개수를 10개로 고정시키고, 변수에 따라 동적으로 xtick 간격을 조정하는 코드입니다. scalse 라이브러리의 pretty_breaks 라는 함수를 사용합니다.
def myConcat(*cols):
concat_columns = []
for c in cols[:-1]:
concat_columns.append(F.coalesce(c, F.lit("*")))
concat_columns.append(F.lit("\t"))
concat_columns.append(F.coalesce(cols[-1], F.lit("*")))
return F.concat(*concat_columns)
# combined column 에 모든 변수를 \t 로 concat 한 값 저장
data_text = data.withColumn("combined", myConcat(*data.columns)).select("combined")
data_text.coalesce(1).write.format("text").option("header", "false").mode("overwrite").save(path)