x1, x2 ... 가 주어졌을 때, Y를 예측하고 싶다. 근데 특정 조건하에서 Y 는 정해진 값이 아니라 어떤 분포를 따른다고 가정하고, 그 평균을 예측하고 싶을 때, 일반화 선형 모형을 활용한다. 기본적인 회귀분석에서는 반응변수가 정규분포를 따른다고 가정하고 모델링하는데, 일반화 선형 모형은 Y가 다른 분포를 따르는 경우에도 활용할 수 있는 모델링 방법이라고 볼 수 있다.
일반화 선형모형에서는 반응변수가 어떤 분포를 따른다고 가정하기 때문에 랜덤성분 (random component) 이라고 부르고, 반응변수의 평균을 설명하기 위한 설명 변수들의 함수 (위 식에서 우측부분) 를 체계적 성분 (systematic component) 이라고 부른다. 랜덤성분과 체계정 성분을 연결하는 함수를 연결함수(link function) 라고 부른다.
Y가 정규분포를 따른다면, 평균값이 -무한대~+무한대일 수 있고, Y 가 베르누이 분포를 따르면 Y의 평균이 0~1사이의 값이다. 따라서 적당한 연결함수를 통해 값의 범위를 변환하는 것이 필요하다.
또한, 일반화 선형 모형에서는 Y 가 지수족 분포를 따른다고 가정한다. 지수족 분포에는 정규분포, 이항분포, 포아송분포, 감마분포 등이 있다. Y가 따른다고 가정한 분포에 따라 알맞는 연결함수를 적용해준다. GLM 에서 지수족 분포가 중요한 개념이지만, 다소 심플하게 내용을 설명하기 위해 지수족 관련 내용은 설명하지 않겠다.
만약, Y가 정규분포를 따르는 경우에 가장 기본적으로 항등함수를 이용할 수 있다. 연결함수가 항등함수인 경우, 일반 선형 모형이라고 한다. (general liner model) (generalied linear model 과 다르다.).
$$ \mu = \alpha + \beta x $$
연결함수가 항등함수인 경우 beta 값의 해석은 매우 쉽다. "X가 1단위 증가했을 때 반응 변수가 beta 만큼 증가한다" 고 해석한다.
Y가 베르누이분포를 따르는 경우 0~1의 값을 무한대로 변환하는 연결함수로 여러가지를 이용할 수 있다. 가장 대표적인 것이 로짓함수이다. 로짓함수를 사용한 변수가 1개인 일반화 선형모형은 아래와 같이 정의된다. 이를 로지스틱 회귀분석 (logistic regression) 이라고 부른다.
$$ log(\frac{\mu}{1-\mu}) = \alpha + \beta x $$
좌측을 살펴보면 log odds 라는 것을 알 수 있다. (=> log(성공확률/실패확률) 이므로) 즉, 로지스틱 회귀분석은 log odds 를 설명변수들의 조합으로 예측하는 것을 의미한다. odds 가 아닌 확률(평균) 의 관점에서 로지스틱 회귀분석은 아래와 같이 써볼 수 있다.
또한 로지스틱 회귀 분석에서 중요한 것은 beta 값의 해석이다. 만약 x가 연속형인 경우 x+1과 x의 odds 를 구해서 odds ratio 를 구해보자. 위 식에 넣어 계산해보면, OR = exp(beta) 가 나온다. 양변에 log 를 취해주면 log(OR) = beta 라는 것을 알 수 있다.즉, x가 1단위 증가했을 때의 log(OR) 값이 beta 라는 것을 알 수 있다.
한편, Y가 베르누이 분포를 따르는 경우에 사용할 수 있는 다른 연결함수로는 프로빗 연결함수가 있다. 프로빗 연결함수를 사용한 일반화 선형 모형을 프로빗 모형이라고 부른다. 프로빗 모형은 표준정규분포의 누적분포함수의 역함수를 연결함수로 사용한다. 누적분포함수의 역함수를 연결함수로 사용한다는 의미가 무엇일까? 누적분포함수는 0~1사이의 값을 갖는다. 즉, 어떤 -무한대~무한대에 있는 X라고하는 값을 0~1 사이로 변환하는 함수이다. 이에 역함수이기 때문에 0~1사이의 값을 -무한대~무한대로 바꾸어주는 함수가 된다.
도수 자료의 경우에는 일반화 선형모형중 포아송 회귀분석을 해볼 수 있다. 도수 자료란 반응 변수가 도수 (count)로 이루어진 자료를 의미한다 (예를 들어, 교통사고 수, 고장 수 등...). 도수자료는 양의 방향에서만 존재한다. 교통사고수가 마이너스일 수는 없다. 반면, 설명변수의 조합인 체계적 성분은 -무한대~무한대의 범위를 갖는다. 이를 변환하기 위해서, 포아송 회귀분석에서는 연결함수로 log 를 활용하여 좌변이 -무한대~무한대의 값을 갖도록 변환한다. 포아송 회귀분석 식은 아래와 같다.
$$ log(\mu) = \alpha + \beta x $$
이는 평균의 관점에서는 아래와 같이 쓸 수 있다.
$$ \mu = exp(\alpha + \beta x) $$
x가 t일 때와 t+1일때의 mu 값을 비교해보자. 위 수식에 대입하면x가 t+1 일 때의 mu 와 t 일 때의 mu 의 ratio 는 exp(beta) 가 됨을 알 수 있다. 즉, 포아송 회귀분석과 같은 log linear regression 에서 beta 를 해석하는 방법은 "x 가 1단위 증가했을 때 Y값의 평균이 exp(beta)배 증가한다." 이다.
포아송 회귀 관련해서는 종종 이런 문제가 발생할 수 있다. 만약, X가 차량 사고수에 미치는 영향을 포아송 회귀로 모델링을 하려고하는데, 지역별로 데이터가 수집 되었고, 지역별로 기본적인 차량의 개수가 달라 사고수가 이에 영향을 받는다고 해보자. 이 때, "사고율" 을 반응 변수로해서 모델링할 수 있다. 차량의 개수를 t라고 하자.
$$ \log(\mu / t) = \alpha+\beta x $$
사고수의 관점에서 아래와 같은 수식으로 변환할 수 있다. 이 때, log(t) 를 offset 이라고 한다.
선택편향은 특정 그룹을 선택해서 분석했을 때, 다른 그룹 또는 전체를 대상으로 분석했을 때와 다른 결론이 나오는 것을 의미한다. 아래와 같이 왼쪽 그림에서는 X,Y 의 연관성이 없지만, X+Y가 1.2 이상인 그룹만 선택해서 봤을 때는 X,Y의 음의 상관성이 생기는 것을 알 수 있다. 이러한 선택 편향은 우리의 실생활에서도 많이 발생한다.
Collider bias
Collider bias는 X와 Y가 모두 영향을 미치는 Z라고 하는 변수가 있을 때, Z를 고정시켜 놓고 보면, X (exposure) 과 Y (outcome) 에 연관성에 편향이 생기는 현상을 의미한다.
왜 Collider bias 가 발생할까? 이에 대해 사고적으로 이해하는 방법에는 "explaining away" 라고 하는 개념이 있다. 예를 들어, X 를 통계학 실력이라고 하고, Y를 아첨 능력이라고 하자. 그리고 X,Y 가 모두 승진 (Z) 에 영향을 준다고 해보자. 이 때, 승진 대상자만을 놓고 통계학 실력과 아첨 능력의 관계를 보면 둘 사이에는 음의 상관성을 확인할 수 있다. (이는 정확히 위 selection bias 에서 설명하는 그림과 같다.)
이처럼 실제로는 통계 실력과 아첨 능력에는 아무런 상관성이 없으며, 승진에 영향을 주는 원인 변수일 뿐인데, 승진 대상자를 놓고 봤을 때는 둘 사이에 연관성이 생긴다 (false association). 승진한 어떤 사람이 아첨능력이 매우 좋다고 했을 때, 이것이 승진의 이유를 explain 해주므로, 이 사람의 통계학 실력은 좋지 않을 것이라고 '추정' 할 수 있을 것이다. 또한, 어떤 사람이 통계 실력이 매우 좋지 않음에도 불구하고 승진했을 때, 이 사람은 아첨 능력이 뛰어날 것이라고 추정할 수 있다. 이처럼 둘 사이에 음의 상관성이 존재하는 것을 직관적으로 이해할 수 있다.
범주형 자료 분석에서 코크란-멘텔-헨젤(Cochran-Mantel-Haenszel) 검정의 목표는 Z 가 주어질 때, X와 Y가 조건부 독립인지를 검정하는 것이다.즉, Z를 고려했을 때, X-Y의 연관성이 존재하는지를 판단하는 검정이라고 할 수 있다. 이는 인과추론에서 말하는 X,Y가 조건부 독립 (conditional independence) 인지를 확인하는 검정이라고 할 수 있다. 보통 Z는 confounder 로 설정하는 경우가 많다. 만약, conditional independence 가 아니라고 한다면, Z 를 고려함에도 X-Y 연관성이 존재하는 것이고, 이는 X,Y 의 인과성에 대해 조금 더 근거를 더해준다고 할 수 있다. CMH 검정은 2 X 2 X K 표에 대해서 활용할 수 있다. (K 는 Z의 수준 개수)
그룹 i 에서의 흡연과 폐암의 연관성
폐암X
폐암O
흡연X
a
b
흡연O
c
d
주요 지표
n = a+b+c+d
p1 = (a+b)/n (흡연X 비율)
p2 = (a+c)/n (폐암X 비율)
m = n*p1*p2
CMH 통계량의 계산
그룹 i 에서의 CMH 통계량은 아래와 같다.
$$ \frac{(a-m)^2}{m(1-p_1)(1-p_2)} $$
최종적인 CMH 통계량은 모든 그룹 i에서 위 값을 다 구해서 더한 것이다. 이 값은 자유도가 1인 카이제곱분포를 따른다는 것을 이용해 검정한다. 만약, 충분히 이 값이 큰 경우 그룹을 고려했을 때, 흡연과 폐암에 연관성이 있다고 결론을 낼 수 있다.
위 수식에서 a-m 은 관측값에서 기대값 (평균) 을 빼준 것이고, 분모는 a의 분산을 의미한다. 이 분산은 초기하분포의 분산이다. 즉, cmh 통계량에서는 a가 초기하분포를 따른다고 가정한다. 즉, 수식은 a 에서 평균을 빼주고 표준편차로 나눈 값에 제곱이라고 할 수 있다.
MH 공통 오즈비
그룹1
X
O
X
10
20
O
30
40
=> OR = 10*40 / 20*30 = 2/3
그룹2
X
O
X
4
1
O
1
4
=> OR = 4*4 = 16
1) 두 그룹의 공통 오즈비를 구하는 방법에는 단순히 두 그룹의 오즈비의 평균을 구하는 방법이 있을 수 있다. 이 경우 그룹2의 샘플수가 적음에도 불구하고 평균 오즈비는 8에 가깝게 높게 나온다.
2) a*d 의 값을 모두 더한 값을 b*c 를 모두 더한 값으로 나누어주는 방법이 있다. 이러면 (10*40 + 4*4) / (20*30+1) = 0.69 가 나오게 된다. 이 값은 샘플수가 많은 그룹의 값으로 지나치게 치우친다.
3) MH 공통 오즈비는 중도적인 방법으로 두 방법의 단점을 보완한다. 2) 방법에서 샘플수의 역수로 가중치를 줌으로써, 샘플수가 많은 그룹이 계산에 미치는 영향력을 의도적으로 줄여준다.
(10*40/100 + 4*4/10) / (20*30/100 + 1/10) = 0.91
즉, MH 공통 오즈비를 사용하면, 지나치게 그룹1에 치우치지 않으면서 적당한 공통 오즈비가 추정된다. 또한, 로그 MH 공통 오즈비의 분산을 계산할 수 있기 때문에, 공통 오즈비의 신뢰구간 및 오즈비가 유의미한지를 추론할 수 있다는 장점이 있따.
예를 들어, 공통 오즈비가 0.91인 경우 로그 공통 오즈비는 -0.094이다. 그리고, 로그 공통 오즈비의 표준편차를 예를 들어 0.02라고 하자. 그러면 공통 오즈비의 95% 신뢰구간은 아래와 같이 계산된다.
비율의 비와 오즈비는 어떤 treatment의 효과(effect) 를 설명할 때 좋다. 비율의 비는 특히, 설명할 때 좋다.
- 예를 들면, 어떤 위험인자가 질병에 미치는 영향이 있는지를 설명할 때는 비율의 비를 활용하는 것이 좋다.
- 흡연의 reltavie risk 가 3이라는 말은 흡연을 하면 폐암 발생 위험을 3배 높인다고 해석할 수 있다.
비율의 차는 전체 모수에서의 impact 를 설명할 때 좋다.
- 어떤 요인 A의 risk difference 는 10% 인데 relative risk 는 2라고 하자.
- 어떤 요인 B 의 risk difference 는 1%인데 relative risk 는 10이라고 하자.
- 이 때, 요인 B 의 effect size는 더 크지만, 실제 요인의 중요도는 A가 더 클 수 있다.
오즈비는 y=1의 비율이 적을 때, 상대위험도와 값이 유사하다.
- 만약의 y가 폐암과 같이 질병인 경우, P(Y=1) 은 유병률이다.
- 즉, 유병률이 작은 질병의 경우 오즈비를 relative risk 처럼 해석할 수 있다.
오즈비는 샘플이 불균형하게 추출한 경우에도 사용할 수 있는 지표이다.
- 비율의 차 또는 비율의 비는 샘플링 바이어스의 영향을 받는다.
- 만약, 흡연자 100명, 비흡연자100명을 선정해서 폐암여부를 비교할 때 비율의 비(relative risk) 에는 bias 가 생긴다. 이는 모집단에서 계산한 값과 차이가 생긴다는 의미이다.
- 그러나, 오즈비의 경우 모집단에서의 값과 오즈비와 비교하여 bias 가 없게 된다.
- 왜 오즈비는 샘플링 영향이 없는지 관련해서는 이 포스팅을 참고할 수 있다.
ratio 에 로그를 취한 값은 유용하다.
- 비율의 비 또는 오즈비는 매우 skew 된 값이다.
- ratio는 0에서 무한대의 값을 갖는다.
- ratio 에 log 를 취해주면 -무한대~ +무한대의 값을 갖게 된다.
- 만약, 어떤 A약의 효과가 B약의 효과보다 1.5배 있다 라는 것을 반대로 말하면 B 약의 효과가 비 약의 효과보다 1/1.5배 = 0.67배 있다라는 것이다. 그러나, 1.5배와 0.67배가 한눈에 역수 관계에 있다는 것을 알기 어렵다. 1.5배는 1로부터 0.5 떨어져 있고, 0.67은 1로부터 0.33 떨어져있다. 만약, 1.5와 0.67에 log를 취해주면, 각각 0.405, -0.405로 나오게 되어, 역관계에 있다는 것을 바로 확인할 수 있다.
X-> Y 의 인과적 관계 파악을 위해, 간단한게 심플 회귀 분석을 진행할 수 있다. 만약 X 와 correlation 이 있고, Y 의 determinants 인 Z 라고 하는 변수가 보정되지 않는다면, omitted variable bias 가 발생한다. 이러한 상황에서 omitted variable bias 의 방향은 다음과 같이 알 수 있다.
1) Z->X 에 영향을 주는 방향
2) Z->Y 에 영향을 주는 방향
1) 2) 를 곱하면 이것이 bias 의 방향이 된다.
예를 들어, 소득(X)이 의료비 지출(Y)에 주는 영향을 파악하려고 한다. 이 때, 건강 상태(이를 개인이 갖고 있는 질병의 갯수라고 하자) 를 보정하지 않으면, omitted variable bias 가 발생하게 된다.
질병의 개수는 소득에 negative effect 이다. 질병의 개수가 증가할 수록 소득은 감소한다.
질병의 개수는 의료비 지출에 positive effect 이다. 질병의 개수가 증가할 수록 의료비 지출은 증가한다.
1) 2) 를 곱하면 negative 가 되기 때문에 bias 의 방향은 negative 가 된다. 따라서 건강 상태를 변수로 포함하지 않고 소득과 의료비 지출의 관계를 파악하여 나온 회귀 계수는 underestimate 이 되었다고 볼 수 있다. 만약, 동일한 건강상태에 있는 사람들만을 대상으로 소득과 의료비 지출의 연관성은 더욱 강하게 측정될 것이다.
충분 통계량 (sufficient statistics) 란 계수를 설명할 수 있는 충분한 정보를 가지고 있는 통계량입니다. 예를 들어, 평균이 theta 이고 분산이 1인 정규분포에서 X1,X2,X3...Xn을 관찰하였고, X의 표본 평균값을 구해서 3이 나왔습니다. 그러면 X의 평균값 이외에 X1,X2,X3,...Xn 각각에 대한 데이터를 추가적으로 봄으로써 theta의 추정에 도움이 되는 다른 정보를 얻을 수 있을까요? 만약 추가적인 정보가 없다면, X의 표본 평균은 theta 를 설명할 수 있는 충분한 통계량이라고 볼 수 있습니다. 좀더 포멀하게는 아래와 같이 충분 통계량을 정의할 수 있습니다.
$$ f(X|Y;\theta) \ne g(\theta) $$
위 식을 만족하면 Y는 theta 에 대한 충분통계량입니다. 위 식의 의미는 Y가 주어졌을 때, X의 pdf 가 theta 에 의존적이지 않다라는 의미입니다. 즉, Y가 theta 에 대한 모든 정보를 갖고 있다는 의미입니다.
충분 통계량의 예시
예를 들어, 베르누이를 2회 시행해서 X1,X2 를 구했다고 합니다. X는 0 또는 1의 값을 갖습니다.
이 때, X1 + X2 는 베르누이의 모수 p 에 대한 충분 통계량일까요?
만약 X1+X2가 0이라면, X1,X2가 가질 수 있는 경우의 수는 (0,0) 입니다.
만약 X1+X2가 1이라면, (0,1), (1,0) 입니다.
만약 X1+X2가 2라면 (1,1) 입니다.
즉, X1+X2 가 주어졌을 때, (X1,X2) 의 분포 (pmf) 는 theta 와 독립적입니다. 따라서 X1+X2 는 충분 통계량이라고 볼 수 있습니다. 이 의미는 만약에 X1+X2 가 1이라고 한다면, X1이 1이냐, X2가 1이냐는 적어도 계수를 추정함에 있어서 중요하지 않다는 것입니다. 위 예시에서는 베르누이 2회 시행에서 예시를 들었으나, N번의 베르누이 시행에서도 X1+...+Xn은 충분 통계량입니다. 만약 100번의 베르누이 시행에서 53번 성공했다라고 한다면, 몇 번째 시행에서 성공했는지는 계수 추정에 있어서 추가적인 정보를 주지는 않습니다.
MLE는 관측한 데이터를 가장 잘 설명할 수 있는 계수(parameter) 를 찾는 것이 목적이라고 할 수 있습니다. 데이터 분석을 하다보면 데이터를 관측하고, 이를 통해 모델의 계수를 추정해야할 때가 있습니다. 우선likelihood 를 정의해보면, 특정 계수에서 데이터를 관찰할 가능성을 의미합니다.
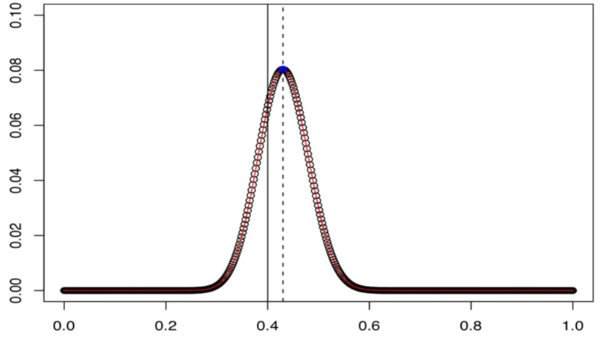
예를 들어, 계수가 0.4인 베르누이분포를 100번 시행해서 45번의 성공이 발생했다고 합시다. likelihood 란 계수의 함수이며, 이 경우에서는 아래와 같이 나타낼 수 있습니다.
이 그래프는 계수가 0.1일 때 데이터를 관찰할 확률, 0.2 일때 관찰할 확률 등등.. 그 값을 모두 구해 계수와 likelihood 의 관계를 나타내는 그래프라고 볼 수 있습니다. 이 때, likelihood 는 계수가 0.45 일 때 최댓값을 갖습니다. 따라서 MLE 는 0.45 입니다. 이 경우 MLE 와 실제 계수에 차이가 있습니다. 하지만, 관측하는 데이터의 갯수가 증가할 수록, MLE 는 실제 계수인 0.4로 수렴해갈 것입니다 (하지만 모든 분포에서 실제 계수에 수렴하게 되는 것은 아닙니다).
x축: 계수 추정값 / y축: likelihood
Probability와 Likelihood 는 다른 개념입니다.Likelihood 는 데이터가 주어져있고, 이를 통해 계수를 추정하기 위한 것이라고 볼 수 있습니다. Probability 란, 어떤 모델의 계수가 주어졌을 때, 특정 outcome 을 예측하기 위한 것입니다.
Maximum likelihood 를 만드는 지점을 찾기
그러면 likelihood function 의 값을 최대화하는 계수값을 어떻게 구할 수 있을까요? 일반적으로는 likelihood function 을 미분해서 값이 0인 지점을 찾으면 됩니다. 또는 계산상의 이점을 위해 log likelihood 를 미분해서 값이 0이 되는 지점을 찾습니다. likelihood 를 미분해서 0이 되는 지점이나, log likelihood 를 미분해서 0이 되는 지점이나 값은 같기 때문입니다.
예를 들어, 앞서 살펴본 베르누이 분포에서 MLE 를 통해 계수 추정을 해봅시다. 베르누이 분포의 pmf 는 아래와 같이 정의 됩니다.
위 score를 0으로 만드는 theta (계수) 값은 표본 평균입니다. (이와 같이 많은 경우, MLE 는 표본 평균인 경우가 많습니다.)
$$ \hat{\theta} = \bar{X} $$
또한 이 경우 표본 평균의 기댓값이 모평균이기 때문에 unbiased estimation 이라고 볼 수 있습니다.
MLE 는 항상 unbiased 는 아니다.
하지만 MLE 의 경우 모든 경우에 unbiased 인 것은 아닙니다. 예를 들어, uniform distribution(0,theta) 의 계수를 MLE 로 추정값은 관측한 데이터중 최댓값이 됩니다(관련된 자세한 설명은 생략하겠습니다). 그리고 이값의 기댓값은 아래와 같이 n에 의존하는 값이 되기 때문에 biased estimation 이라고 할 수 있습니다.(참고링크)
MLE 의 분산과 Efficiency
그럼에도 불구하고 MLE 는 관측 데이터가 많으면 많을 수록 가능한 unbiased estimator 집합들이 가질 수 있는 분산의 최솟값으로 수렴한다는 큰 장점을 가지고 있습니다. 즉, MLE 는 이론적으로 나올 수 있는 가장 작은 분산을 가진다는 의미이며, 이를 "Asymptotically efficient 하다" 라고 부르기도 합니다.
이 때, 이론적으로 나올 수 있는 분산의 최솟값을 Rao-Cramer Lower Bound 라고 부릅니다. 어떤 unbiased estimator Y가 있을 때, Y의 분산의 최솟값은 아래과 같습니다.
$$ var(Y) \ge \frac{1}{nI_1{\theta}} $$
여기서 I는 fisher information 이고 아래와 같습니다. I_1 은 데이터 하나로 구한 fisher information 입니다.
$$ I(\theta) = E(-l''(\theta)) $$
$$ I(\theta) = nI_1(\theta)$$
베르누이 분포에서 fisher information 과 rao-cramer lower bound 를 구해봅시다. 데이터 1개에서 log likelihood 를 구하면 fisher information 을 구하고 이를 통해 rao-cramer lower bound 를 구할 수 있습니다.
이 값은 rao-cramer lower bound 의 값과 같습니다. 따라서 베르누이 분포에서 MLE 는 최소 분산을 가지며, efficient estimator 라고 할 수 있습니다. 또한 unbiased 이기 때문에, minimum variance unbiased estimator (MVUE) 라고 부르기도 합니다.
t-SNE (t-distributed Stochastic Neighbor Embedding) 는 고차원 데이터를 저차원 데이터로 변환하는 차원 축소 (dimensionality reduction) 기법이며, 대표적이며, 좋은 성능을 보이는 기법이다.
차원 축소을 하는 목적은 시각화, 클러스터링, 예측 모델의 일반화 성능 향상 등의 목적을 들 수 있다. t-SNE 의 경우, 고차원 공간상의 데이터 포인트들의 위치를 저차원 공간상에서의 극적으로 표현을 해주기 때문에 데이터에 존재할 수 있는 군집들을 시각화해서 표현해주는데 강점을 갖고, 시각화에 주로 사용된다. t-SNE 는 직접적으로 클러스터를 만들어서 레이블링까지 해주는 클러스터링 알고리즘은 아니다. 따라서 클러스터링에 직접적으로 활용되기 보다는 t-SNE 의 결과에 다시 k-means 와 같은 알고리즘을 적용하는 방식으로 클러스터링을 수행하기도 한다 (참고: https://www.quora.com/Can-TSNE-be-used-for-clustering). t-SNE 는 PCA 와 같이 저차원에서 요약된 변수에 의미가 있는 것은 아니다. (PCA 의 경우, 저차원 공간의 변수가 고차원 공간상의 변수들의 선형 결합이라는 의미가 있다.)
차원 축소의 3가지 카테고리
1) feature selection: univariate association test, ensemble feature selection, step-wise regression 등
3) neighbor graphs: t-sne, UMAP (Uniform Manifold Approximation and Projection) 등
우선, t-sne 는 비선형 차원 축소 (nonlinear dimensionality reduction) 기법이다. 따라서 아래와 같은 데이터에 대해서도 적용할 수 있다. 반면 PCA (principle component analysis) 와 같은 선형 차원 축소 방법의 경우 아래 데이터에 적용하여 유의미한 결과를 내기는 어렵다.
선형 차원 축소 기법으로 차원 축소가 어려운 형태의 데이터
t-SNE 알고리즘
sne, t-sne, UMAP 과 같은 차원 축소 방법은 아래의 공통된 절차를 수행한다.
원래 데이터가 있는 공간을 high dimension, 축소된 공간을 low dimension 이라고 하자.
1) high dimensional probabilities p 를 계산한다. 2) low dimensional probabilities q 를 계산한다. 3) 두 분포의 차이를 반영하는 cos function C(p,q) 를 정의한다. 4) Cost function 이 최소화 되도록 저차원 공간상의 데이터를 변환한다.
대략적인 절차는 매우 심플하다. t-sne 에서는 각 절차를 실제로 어떻게 수행하는지 알아보자.
1) high dimensional probabilities p 를 계산한다.
p_(i,j) 를 어떤 데이터 포인트 i,j의 similarity 를 반영하는 스코어라고 하자. 두 포인트가 가까이 위치할 수록 p_(i,j) 의 값은 커지게 된다. 그리고 i,j 의 euclidean distance 를 e_(i,j) 라고 하자. 다른 데이터들에 대해서도 서로의 eucliean distance 를 계산할 수가 있고, 그 값들이 어떤 분포 g 를 따른다고 가정하자. p_(i,j) 는 그 분포상에서의 likelihood 라고 할 수 있는, g(e(i,j)) 로 정의해보자.
예를 들어 설명하면, 위 두 데이터 포인트를 각각 (2,9) 와 (3,10) 이라고 하자. e= sqrt((3-2)^2 + (10-9)^2)=sqrt(2) = 1.41 이다.
그러면, p(j|i) 의 값이 p(i|j) 의 값은 다른데, 최종적으로 두 값의 평균을 취하고, 마찬가지로 모든 값의 합이 1이 되도록 하기 위하여 최종적인 i,j 의 similarity score p(i,j) 를 아래와 같이 계산한다 (N은 계산 가능한 쌍의 수). 이러면, p 를 이산확률분포처럼 다룰 수 있게 된다.
이를 위해하기 위해 우선, entropy 와 perplexity 라는 개념에 대한 설명이 필요하다. perplexity = 2^entropy 로 정의되며, entropy 는 '어떠한 확률 분포에 대하여, 관측값을 예측하기 어려운 정도' 를 의미하는 수치이다. 어떤 분포 q 에대한 entropy 는 아래와 같다.
$$ H(q) = -\sum_{c=1}^{C} q(y_c)log(q(y_c)) $$
entropy 를 설명하기 위해, 빨간공과 녹색공이 20:80 으로 들어 있는 가방에서 1개의 공을 꺼내서 관찰 값을 확인하는 이산 확률 분포를 예로 들어보자. 그 확률 분포 q의 entropy 는 H(q)=-(0.2log(0.2)+0.8log(0.8))=0.5 이다. 그리고, perplexity = 2^0.5 = 1.41 이다.
perplexity 값에 따라 t-SNE 의 결과가 민감하게 반응하기 때문에 perplexity 는 중요한 파라미터이다. 보통 t-SNE 는 입력받은 perplexity 를 맞추는 σ 를 찾기 위하여 binary search 를 수행한다. 일반적으로 perplexity 를 조정하면서 시각화를 해보고, 가장 군집을 잘 보여주는 값을 최종적으로 선정하는 방법을 택한다.
왜 p, q 분포는 위와 같이 정해지는가?
p분포는 정규 분포와 유사하며, q분포는 t분포와 유사한 형태를 띈다. q 분포의 경우, p 분포 대비 빠르게 하락하고, 꼬리가 두터운 형태의 분포를 갖는다. q분포를 썼을 때의 효과는 한 점에 데이터가 뭉치는 crowding problem 을 완화시킨다는데 있다. 따라서, 시각화시 저차원 공간상에서 너무 한 점에 뭉치지 않도록 하는 효과가 있기 때문에 p 분포를 썼을 때보다 이점이 있다. (이는 개인적인 이해를 위한 해석이며, 이와 관련한 좀 더 디테일한 설명은 original paper 를 참고)
구현 레벨에서의 최적화
t-SNE 는 데이터가 커질수록 연산량이 기하급수적으로 늘어나는 O(n^2) 의 시간 복잡도를 갖는다. 실제 구현 레벨에서는 Barnes hut t-SNE 라는 방법을 통해 더 계산 효율적인 구현 방식을 택한다. scikit-learn 의 t-sne 구현체는 이 방식을 활용한다.
t-SNE 의 optimization
t-SNE 에서의 optimization 이란 고차원 공간상에서의 p분포 (high dimensional probabilities p) 와 저차원 공간상의 q분포 (low dimensional probabilities q ) 의 차이를 줄이는 것이다. 이 때, cost function 을 정의하고, 이를 최소화하는 방식으로 optimization 이 수행된다.
3) 두 분포의 차이를 반영하는 cos function C(p,q) 를 정의한다.
cost function C(p,q) 로는 Kullback-Leibler divergence 를 사용한다. p,q는 이산확률분포이고, KL divergence의 식에 적용하면 cost 를 실제로 구해볼 수도 있다.
4) Cost function 이 최소화 되도록 저차원 공간상의 데이터를 변환한다.
KL divergence 을 최소화 시키는 저차원 공간상의 데이터의 위치를 gradient optimization 방식을 통해 구할 수 있다. 설명하자면, 결국 저차원 공간상에 랜덤하게 뿌려진 데이터 포인트들이 각각 어떤 방향으로 가야지 cost function 을 줄일 수 있을지 알아야 하는 것인데, 이는 cost function 을 미분한 뒤에 각 데이터 포인트 별로 gradient 를 구함으로써 알 수 있다.
예를 들어, 우리의 친구 Justine 이 좋아할만한 소설을 예측하고 싶다고 가정하자. 현재 가지고 있는 정보는 "그녀가 최근 읽은 몇 가지 소설" 및 "그 소설들에 대해 그녀가 좋아했는지 안 좋아했는지 여부" 를 알고 있다.
표준적인 supervised machine learning 패러다임에서는positive example 과 negative example 들의 feature들을 비교하여, 새로운 소설 (unseen) 에 대해 그녀가 좋아할지 안좋아할지를 예측하는 모델을 만든다.
반면, semi-supervied paradigm 은 Justine 이 읽은 소설만 활용하는 것이 아니라 그녀가 읽지 않은 소설 (unlabeled) 까지 활용하여 그녀가 선호할만한 소설을 예측하는 시스템을 만든다. 당연히 전체 소설중, 그녀가 읽지 않은 소설이 훨씬 많을 것이며, 놀랍게도, 이를 활용하면 (unlabeled 데이터를 활용하면) 더욱 효율적인 시스템을 만들 수 있다는 것이다.
Why semi-supervised learning works?
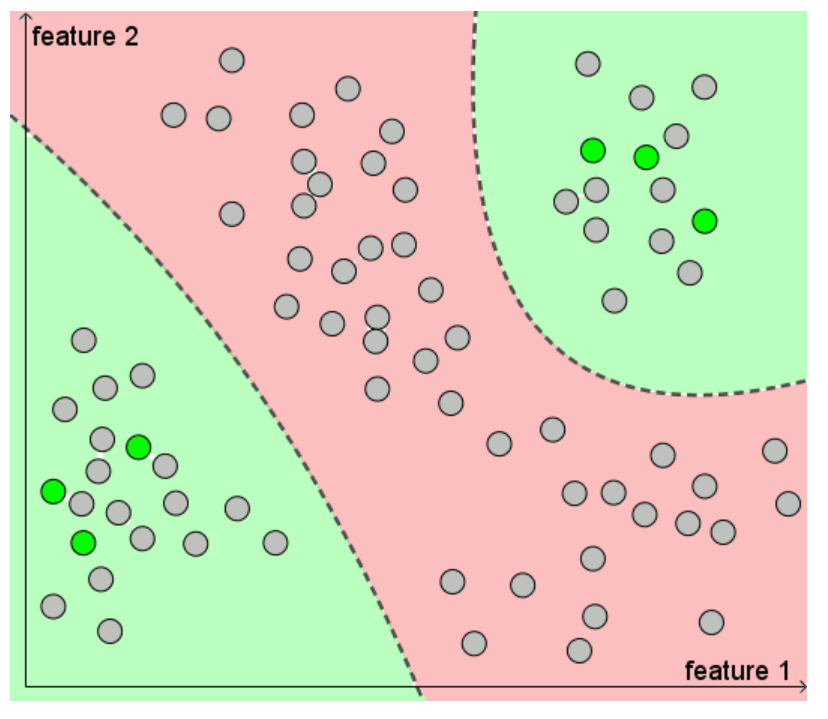
왜 unlabeld 데이터가 예측에 도움이 될 수 있는지를 이해하기 위해 위 그림을 보자.
초록색: positive cases
빨간색: negative cases
선: decision line
unlabeled 데이터를 활용하면 오른쪽 그림처럼 더욱 정교한 decision line 을 그릴 수 있다. 이를 통해 모델의 성능 및 일반화에 도움을 줄 수 있다.
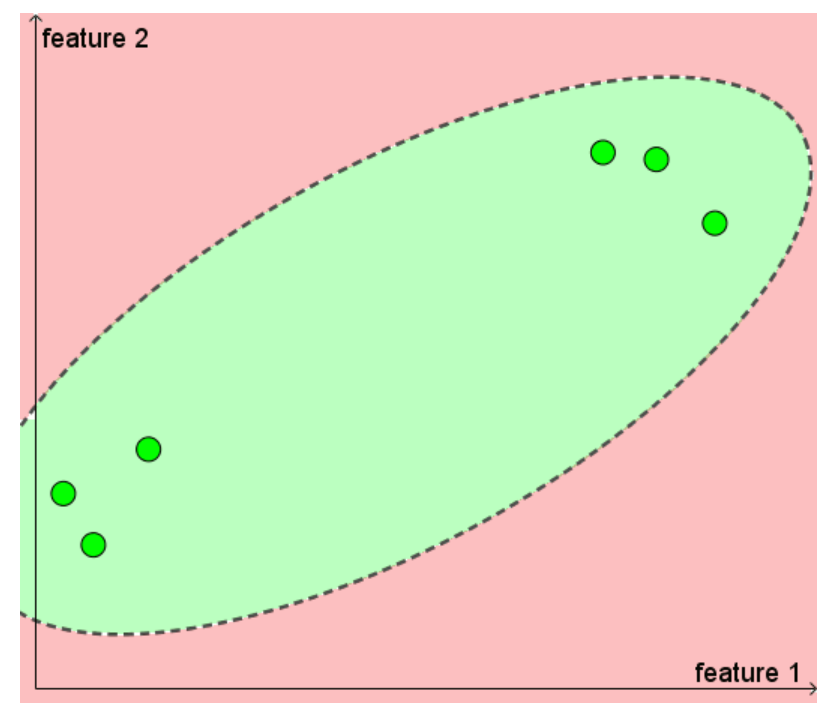
PU learning 의 직관적 이해
Positive-unlabeled learning 은 semi-supervised learning 은 한 가지 패러다임으로, positive case 와 unlabeld case 만 존재하는 문제에서, 사용할 수 있는 방법이다. 위 예시에서 Justine 이 좋아하는 소설에 대한 데이터만 갖고 있는 것이다. real-world 에서 이러한 상황은 생각보다 자주 존재한다. (항상 toy 문제처럼 positive case 와 negative case 가 잘 들어가 있지는 않다.)
초록색: positive cases
선: decision line
PU learning 이 왜 워킹 하는지에 대해 직관적으로 이해해보자.
1) 왼쪽 그림만을 보고, positive와 negative 를 구분하는 선을 만들라고 하면 어떻게 할 것인가? (머신러닝 모델이 아닌 사람의 직감으로) 다른 데이터들이 어떻게 놓여있는지를 알 수 없기 때문에, 타원 모양의 decision boundary 를 그리는 것이 한 가지 방법이 될 것이다.
2) 오른쪽 그림을 보고, 다시 positive 와 negative 를 구분하는 선을 만들라고 하면 어떻게 할 것인가? 왼쪽 그림과 비교하여 추가적인 정보 (unlabeled 데이터가 어디에 놓여있는지) 를 알고 있다. 그렇기 때문에 그림처럼 다른 decision boundary 를 그릴 수 있게 된다.
PU learning 의 몇 가지 테크닉들
1) Direct application of a standard classifier
가장 기본적인 접근 방법은 unlabeled case 를 negative 로 취급하고 분류 모델을 학습하는 것이다. 이 모델은 각 데이터 포인트에 점수를 주는데, positive case 에 대해서 평균적으로 더 높은 점수를 준다. 만약 unlabeled 데이터 중에 높은 점수를 받은 데이터 포인트가 있다면, positive case 일 확률이 높을 것이다.
이러한 '가장 나이브한 방식' 의 정당성은 이 논문에서 확인되었다 (2008년도). 이 논문의 주요 결과는, 몇 가지 특정한 가정하에, positive+unlabeled 데이터로 학습한 모델의 성능은 positive+negative 데이터로 학습한 결과와 비례한다는것이다.
저자의 코멘트에 따르면, 이 의미는 다음과 같다: "모델이 잘 학습되었다고 가정하면, PU 모델은 어떤 데이터 포인트가 positive 에 속할 가능성에 대한 순위를 매기는데 활용할 수 있다."
2) PU bagging
더욱 정교한 접근 방법은 bagging 의 변형을 활용하는 것이다.
- positive data 와 함께 "unlabeled data 로 부터 random sampling 한 데이터(with replacement)" 를 같이 활용한다.
- 위 boostrap sample 을 negative 로 하여 모델을 학습한다.
- out of bag 샘플 (boostrap sample 에 포함되지 않은 unlabled data) 에 대해 스코어를 매기고, 저장한다.
- 이러한 방법을 반복적으로 적용하고, unlabeled 데이터들에 대해 나온 스코어들을 평균낸다.
이러한 접근 방법이 소개된 논문 (2013년) 에서 저자들은 특히, 갖고 있는 positive sample 숫자가 적고, unlabeled 데이터 중, negative 의 비율이 적은 PU learning 상황에서 state-of-the-art 성능을 달성했다고 주장했다 (2013년도 기준). 또한 unlabeled 데이터의 규모가 큰 경우, 이러한 bagging 방식은 더 빠르게 모델을 학습할 수 있다.
3) Two-step approaches
많은 PU learning 전략은 two-step 접근 방법 카테고리에 속한다. (이 방법이 소개된 논문 (2014년))
Step1 - unlabeled 중에 negative 인 것이 가장 확실한 포인트들을 찾는다. (이를 reliable negative 라고 한다.)
Step2 - positive 와 reliable negative 로 모델을 학습하고, 나머지 unlabeled 데이터에 적용한다.
일반적으로 Step2 의 결과를 통해 Step1 으로 되돌아가서, reliable negative 를 찾고 이를 반복하게 된다. 당연히 reliable negative 의 규모가 충분히 크고, 실제 negative 를 많이 포함하고 있을 수록 더 좋은 모델을 구축할 수 있다. 얼마나 반복해서 적절한 수의 reliable negative 를 찾을 수 있을지가 핵심적인 부분이라고 할 수 있다.
최근 다양한 도메인에서 머신러닝이 활용되고 있다. 머신러닝의 문제점은 training data 가 필요하다는 것이다.
현실에서는 label 이 있는 데이터를 수집하기 어렵거나 높은 비용이 요구되는 상황이 많다.
semi-supervised learning 이러한 상황에서 전체 데이터의 일부에만 label 이 있을 때 사용한다.
왜할까?
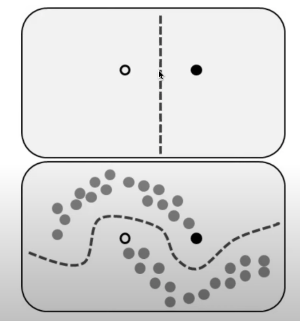
semi-supervised learning 의 핵심 과정 중 하나는 unlabled data 를 labled data 로 변환하는 것이다. (이를 pseudo-labeling 이라고 한다.) 그런데, 전체 데이터의 일부에 lable 이 있다고 하면, 그 데이터를 training 데이터로 모델을 만들면 안 되는가?
위 그림을 보면, 소수의 labeled data 로 만든 decision boundary 보다 unlabled data 를 사용한 것이 더 세밀하다는 것을 직관적으로 알 수 있다. 즉, 더 많은 데이터들에 대한 generalization 이 잘 된다는 것이다.
semi-supervised learning 의 이점
labled data 와 unlabled data 를 combine 하는 것은 accuracy 를 상승시킨다. (may be due to generalization)
unlabled data 를 획득하는 것은 상대적으로 cheap 하다. -> 잘만 되면 더 비용효율적이다.
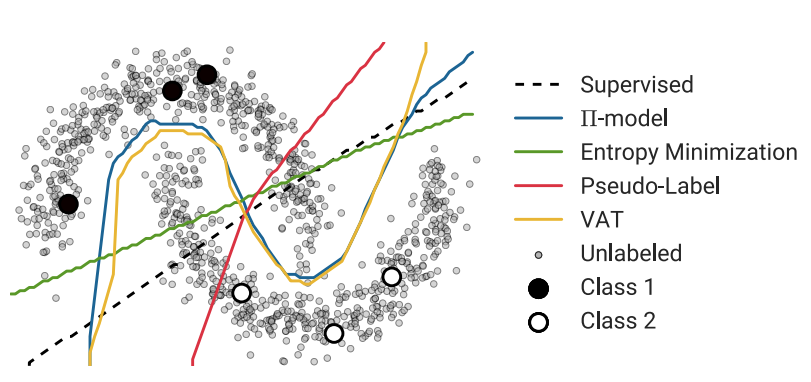
다양한 SSL 방법론에 따른 decision boundaries
semi-supervised learning 의 가정
1) Continuity / smoothness assumption
"다차원 공간 상에서 가까운 거리에 있는 샘플들은 labeld 이 아마 같을 것이다." 라는 가정이다. 이는 지도학습에서도 마찬가지로 있는 가정이다. 다만 semi-supervised learning 에서는 가까운 거리에 있는 샘플들은 예외 없이 같은 label 이 된다. 라는 점이 다르다.
2) Cluster assumption
"데이터는 클러스터를 형성할 것이며, 같은 클러스터에 속한 샘플은 같은 label 을 공유할 가능성이 높다"라는 가정이다. (같은 label 을 가진 샘플들이 다양한 클러스터에 존재할 수는 있다.) 이는 clustering 알고리즘에서의 smoothness assumption 으로 볼 수 있다.
3) Manifold assumption
"고차원 공간의 데이터를 저차원 공간에 표현할 수 있다." 라는 가정이다. 이는 모델링에서는 당연한 가정이라고 볼 수 있다. 예를 들어, 수많은 피쳐 x 를 통해 하나의 y를 예측하는 과정이니 말이다. manifold assumption 성립하지 않으면 예측이 불가능하다고 볼 수 있다.
pseudo-labeling
labeled data 를 통해 unlabled data 를 labled data 로 변환하는 것을 말한다.
Active Learning
labeled data 를 주어진대로만 사용하지 않고, 재구성하는 전략을 말한다.
가장 성능을 높이는데 효과적인 샘플 (labeled or unlabeld) 에 대해 labeling 을 수행하는 전략이다.
supervised learning 에서 학습이 잘되는 일부 labeling data 만 사용할 수 있다.
semi-supervised learning 에서 pseudo-labeling 하는 것도 active learning 의 일종이다.
Margin sampling
margin sampling 은 active learning 의 예시로 decision boundary 를 효율적으로 찾는 방법중 하나로 가장 애매한 (uncertain) 샘플을 labeled data 로 변환해 나가면서 decision boundary 를 업데이트 해나가는 방법이다. 아래와 같이 random 하게 업데이트 하는 것보다 빠르게 클래스를 잘 분류할 수 있는 boundary 를 찾을 수 있다.
Weak supervision
ground truth label 이 없을 때, subject matter expert (SME) 가 휴리스틱한 방법으로 labeling 하는 것을 말한다.
만약 이 방법으로 어떤 샘플이 A 레이블에 할당되었다고 하더라도, 실제로는 A 레이블이 아닐 가능성을 갖고 있다.
이를 noisy label 이라고 한다.
Snorkel
스탠포드에서 2016년에 개발되었다. manual labeling 을 줄이는 방법으로 training data 를 구축하기위한 라이브러리이다. snokel 은 weak supervision 상황을 해결하는 것을 돕는다.
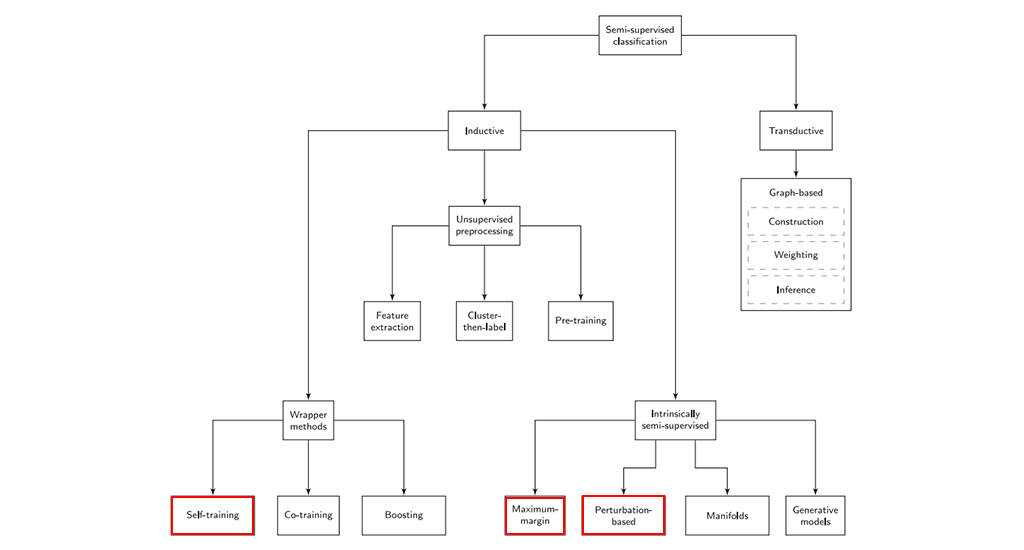
semi-supervised learning 의 분야
semi-supervised learning 의 핵심과정인 pseudo-labeling 을 어떻게 수행할 것인가?
단순히 model prediction 을 통해 pseudo-labeling 을 하는 것보다 성능이 좋은 다양한 방법론들이 존재한다.
위 분류에서는 semi-supervised learning 을 크게 transductive 와 inductive로 나눈다. [1]
ㄴ transductive 와 inductive 의 차이를 데이터 과점에서 본 포스팅 (link)
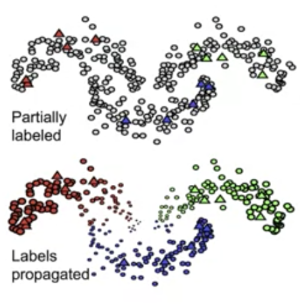
참고자료 [2] 에서는 1) graph-based 방법과 2) consistency-based 방법으로 나누기도했다. Graph-based method은 대표적으로 Label propagation 방법이 있다. consitency-based method 는 최근 각광받고 있는 방법으로 Mixmatch 를 예로 들 수 있다.
참고자료
[1] Van Engelen, Jesper E., and Holger H. Hoos. "A survey on semi-supervised learning." Machine Learning 109.2 (2020): 373-440