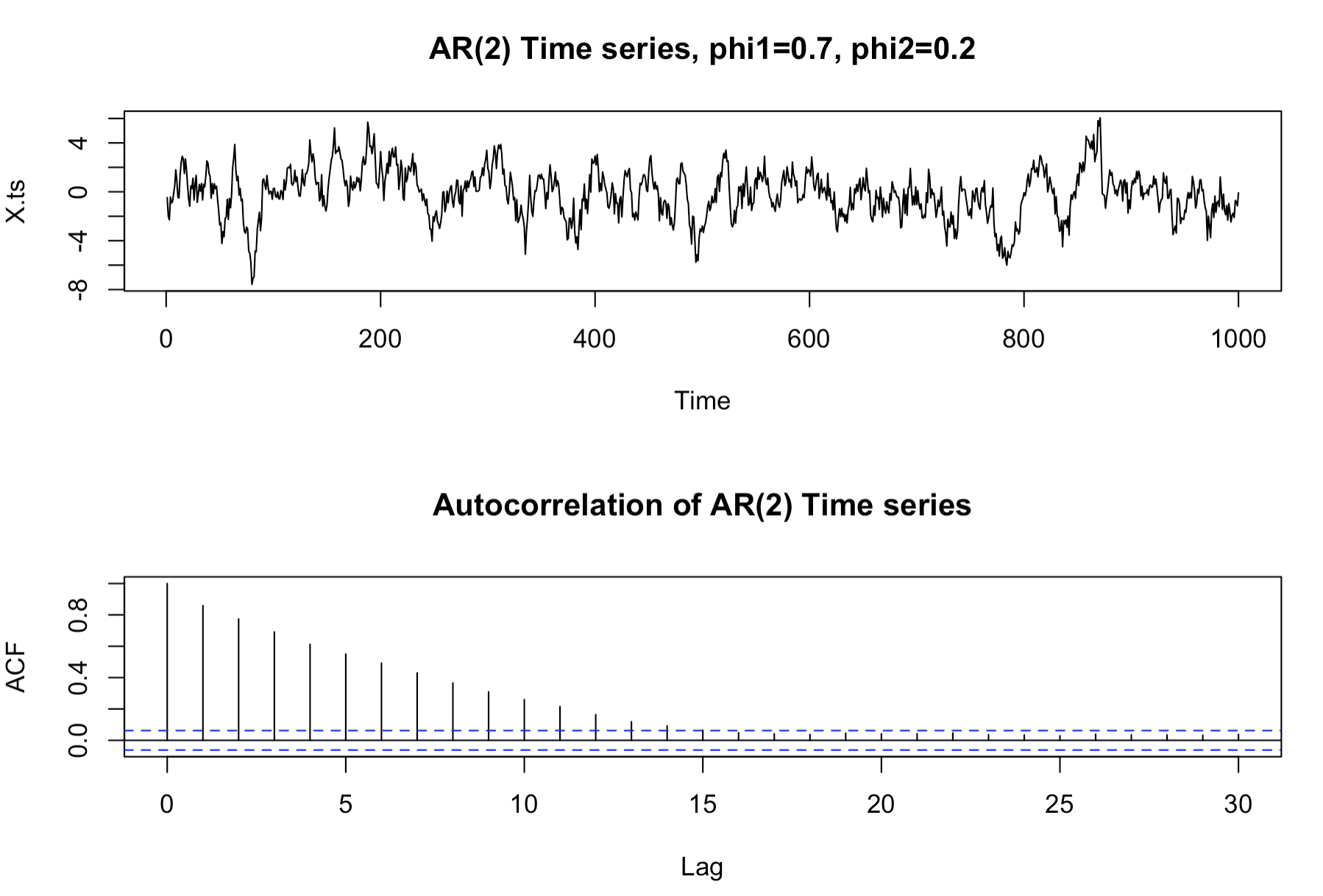
p=2 이고, 가중치가 0.7, 0.2 인 autoregressive process 는 아래와 같다.
$$ X_t = Z_t + 0.7X_{t-1} + 0.2X_{t-2} $$
이를 R 코드로 구현하면 아래와 같다. 선차트를 통해 보면 현재 값이 과거 값과 높은 상관성이 있다는것을 확인할 수 있다. correlogram 을 통해 가까운 시간에 측정된 값이 현재값과 더 높은 상관성이 있다는것을 확인할 수 있다. (가중치가 0.7, 0.2 이므로)
set.seed(2017)
X.ts <- arima.sim(list(ar=c(0.7,0.2)), n=1000)
par(mfrow=c(2,1))
plot(X.ts, main="AR(2) Time series, phi1=0.7, phi2=0.2")
X.acf <- acf(X.ts, main="Autocorrelation of AR(2) Time series")
X.acf
Moving average process 와의 관계
Autoregressive process 는 moving average process 의 무한 수열로 나타낼 수 있다.
차수 (p) 가 1인 AR 을 생각해보자.
아래와 같이 식을 쓸 수 있다. (Z는 평균이 0, 분산이 sigma^2 을 따른다고 가정하고, phi 를 theta 로 치환하자.)
위 AR(1) process 에서 Z 를 제외한 나머지 텀들을 한쪽으로 옮겨서 아래와 같은 식을 만들 수 있다.
$$ \phi(B) = 1-\phi B $$
이 때, 우변을 0으로 만드는 B 의 해를 찾는다. 해는 B = 1/phi 이다. B 의 해가 단위원 (unit circle) 바깥에 있는 것이 stationarity 를 만족하기 위한 조건이 된다. 따라서 AR(1) 모델에서는 phi 의 절댓값이 1 미만이어야 stationarity 를 만족한다.
따라서 Random walk model 의 시간에 따른 평균은 t*mu 이고, 분산은 t*sigma^2 이다. 만약 Z의 평균이 0이라고 가정하더라도 분산이 시간에 따라 점점 커진다는 것을 알 수 있다. 따라서 Random walk model 은 stationarity 를 만족하지 않는다.
moving average 의 parameter q 와 가중치 theta 를 고정해놓고 계산을 하면, 평균과 분산은 t 와는 관계 없이 고정된다는 것을 알 수 있다. 따라서 moving average model 은 stationarity 를 만족한다.
추가적으로 Moving average model 의 auto covariance function 을 구해보자.
moving average model 은 stationarity 를 만족하기 때문에 auto covariance function 은 time spacing 에만 의존한다. 또한 이전 포스팅에서 time spacing 이 최대 q 인 경우에만 자기상관성이 존재한다는 것을 correlogram 을 통해 확인할 수 있었다. moving average model 의 노이즈의 평균이 0일 때를 가정하고 covaraicne 를 구해보자.
특정 시점 t에서의 주가를 X_t 라고하자. 또한 특정 시점 t 에서의 회사의 공지 Z_t (noise) 가 주가에 영향을 미친다고 하자. 그런데 과거 시점 (t-1, t-2...) 에 회사의 공지도 주가에 영향을 미친다. 이런 경우에 X_t 를 다음과 같이 모델링할 수 있다.
# noise 생성
noise <-rnorm(10000)
ma_2 = NULL
# ma(2) 생성을 위한 loop
for (i in 3:10000) {
ma_2[i] = noise[i] + 0.7*noise[i-1]+0.2*noise[i-2]
}
# shift
moving_average_process <- ma_2[3:10000]
moving_average_process <- ts(moving_average_process)
par(mfrow=c(2,1))
plot(moving_average_process, main = "A moving average process of order 2", ylab = "")
acf(moving_average_process, main = "Correlogram of ma (2)", ylab = "")
correlogram 을 보면 time step 이 0,1,2 인 경우에만 상관성이 있는 것을 확인할 수 있다. 우선, time step 이 0 인 경우는 항상 auto correlation coef 1이다. 또한 현재값에는 최대 2 time step 전의 noise 까지 반영이 되기 때문에, 최대 2 time step 의 값과 상관성이 있다는 것을 확인할 수 있따.
아래와 같이 정의되는 X_t 를 random walk 이라고 한다. X_t 는 이전 time step 에서의 값 X_t-1 에 noise Z가 더해진 값이다. random sampling 과 다른점은 현재값이 이전값에 더해진다는것이다. 이는 랜덤하게 어떤 한 방향으로 걷는것과 비슷하다. 매번 시작점에서 한발짝 걷는 것이 아니라 한발짝 걸어서 도착한 곳에서 다시 한발짝을 간다.
$$ X_t = X_{t-1} + Z_t $$
$$ Z_t \sim Normal(\mu, \sigma) $$
이러한 random walk 모델에서 X_t 는 이전 time step 에서의 값 X_t-1 과 매우 큰 연관성을 갖는다. 따라서 non-stationary time series 데이터이다.
Random walk model simulation in R
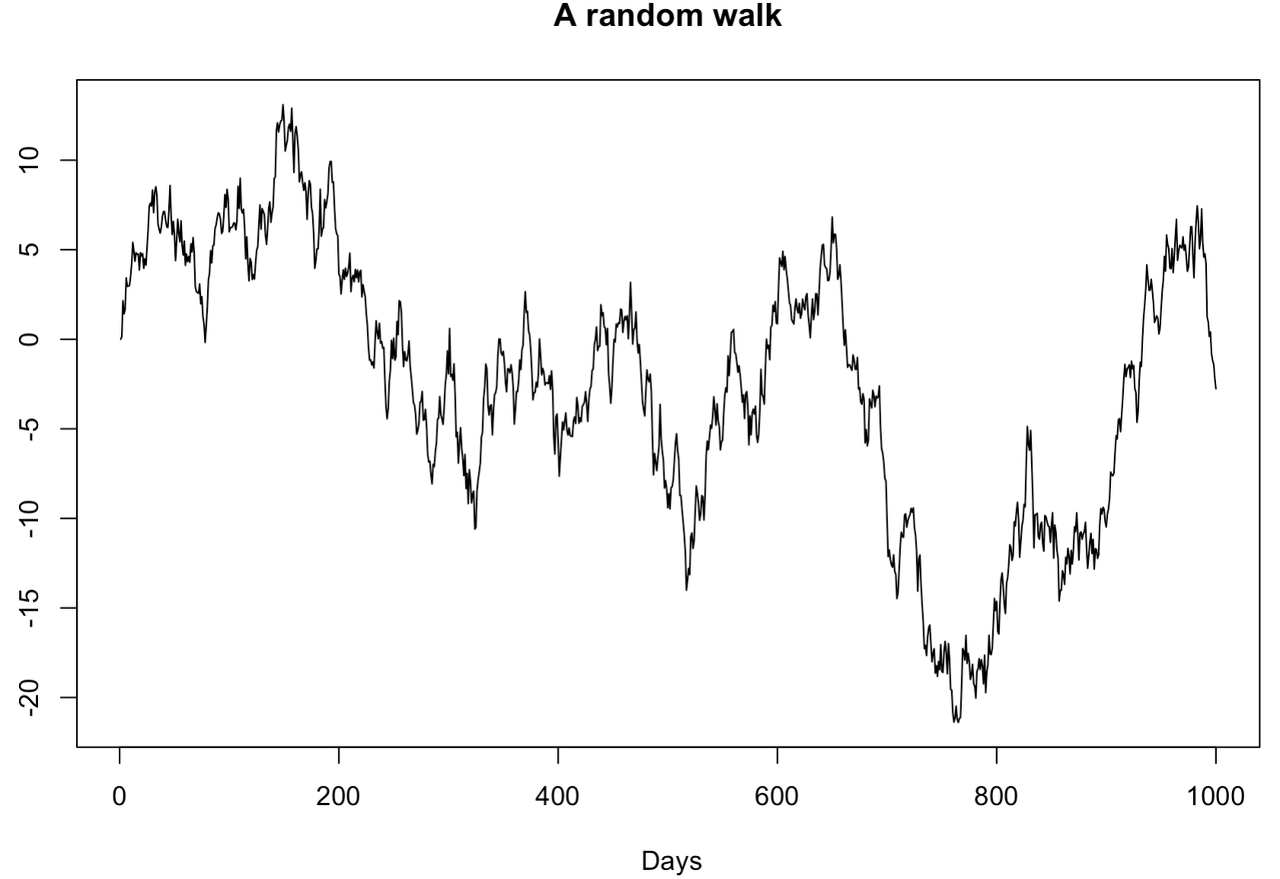
R 로 random walk 모델을 만들어보자. 아래는 1000개의 random walk 데이터를 생성하는 예제이다. 시계열 그래프를 그려보면, 이 데이터는 non-stationary time series데이터라는 것을 확인할 수 있다. 구간을 나눠서보면 트렌드를 보이기 때문이다.
x <- NULL
x[1] <- 0
for(i in 2:1000){
x[i] <- x[i-1]+rnorm(1)
}
random_walk <- ts(x)
plot(random_walk, main="A random walk", ylab="", xlab=" Days", col="black")
위 그림은 전형적인 random walk 그래프이다.
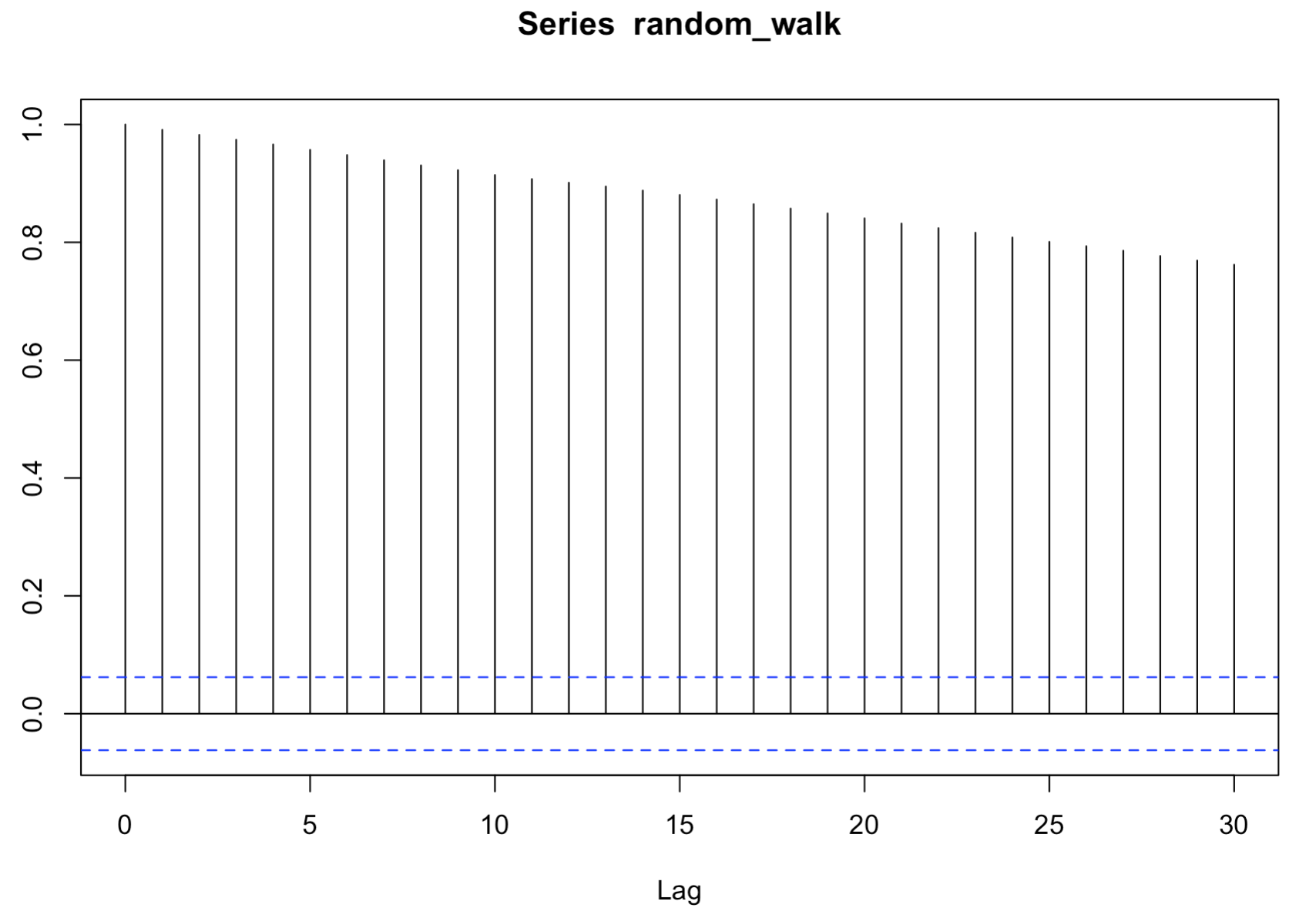
random walk 데이터에서 correlogram 을 그려보자. 인접한 time step 에서 auto correlation coefficient 가 큰 패턴을 보이기 때문에 non-stationary time series 라는 것을 다시 확인할 수 있다.
acf_result <- acf(random_walk)
random walk 모델에서 noise Z는 stationary time series 라고 볼 수 있다.
$$ Z_t \sim Normal(\mu, \sigma) $$
noise 가 stationary time series 라는 것을 데이터로 실제로 확인해보자.
random_walk_diff <- diff(random_walk)
plot(random_walk_diff, main="A random walk diff", ylab="", xlab=" Days", col="black")
앞선 포스팅에서 auto covariance coefficient 에 대해 설명하였다. auto covariance coefficient 은 time series 데이터에서의 각각의 time point 간 연관성을 의미하는데, stationary time series 에서는 k 라고하는 parameter 에 의해 달라진다. auto covariance coefficient 의 추정값 c_k 는 아래와 같이 계산된다.
이번에는 auto correlation coefficient 에 대해 정리해보려고 한다. auto correlation coefficient 도 auto covariance coefficient 와 마찬가지로 time series 데이터에서 time step 별 값의 연관성을 의미하는데 범위를 -1~1로 조정한 것으로 이해할 수 있다. 마치 공분산과 상관계수의 관계와 같다.
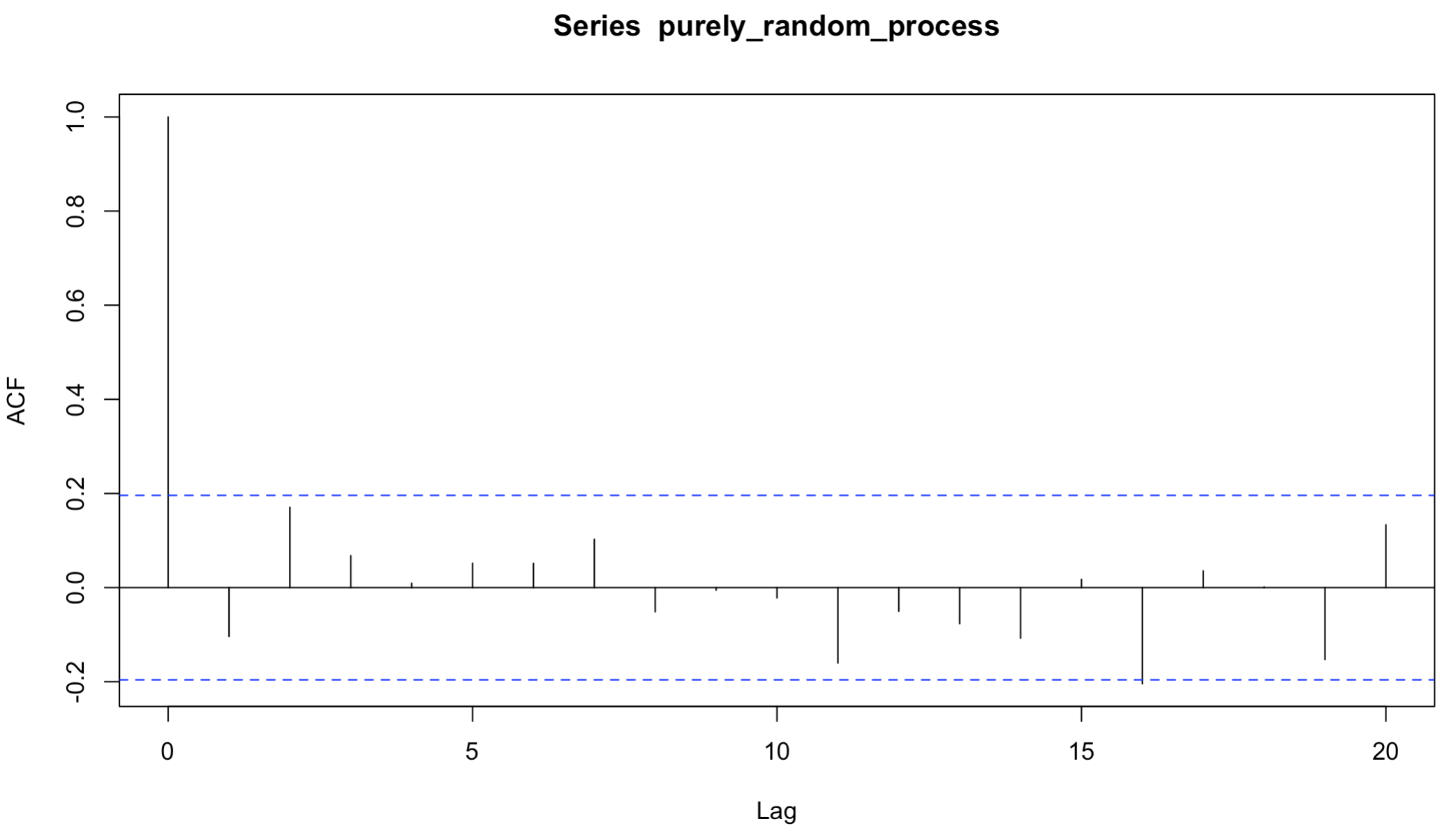
아래 R 코드는 100개의 표준정규분포를 따르는 데이터를 만든 후, correlogram 을 그리는 코드이다. 파란선은 연관성이 유의한지에 대한 임계치를 의미한다. 유의한 데이터 포인트가 하나 밖에 없고, lag 에 따른 패턴이 보이지 않으므로, 전체적으로 시계열 데이터가 자기상관성이 없다고 결론 내릴 수 있다.
실제 데이터를 correlogram 을 그려보자. 다음은 모 어플리케이션의 월간 활성 이용자수 (MAU, monthly active user) 추이이다. 이 서비스는 점점 성장하는 추이를 보여주고 있다. 시계열 데이터의 관점에서는 시간에 따른 평균의 변화 (trend) 를 보이는 non-stationary time series 이다.
위 데이터에서 correlogram 을 그리면 아래와 같이 나타난다. lag 에 따른 auto correlation coef 의 패턴이 보이며 (점점 감소), 인접한 데이터 포인트에서는 유의한 상관성을 보이고 있는 것을 확인할 수 있다.
어떤 종류의 데이터이든 상관 없으며, 그저 시간에 따라 수집된 데이터를 시계열 데이터 (timeseries data) 라고 한다.
한국의 일별 코로나19 신규 확진자수 추이
예를 들어, 일별 코로나 확진자수는 1일이라고 하는 time step 으로 수집된 시계열 데이터의 한 종류이다.
Week stationary time series
week stationary time series 란 다음의 조건을 만족한다.
1) 시간에 따른 평균 (mean) 에 변화가 없다.
2) 시간에 따른 분산 (variance) 의 변화가 없다.
3) 주기적인 등락 (flucation) 이 없다.
이러한 조건을 만족하긴 위해서는 time series 의 한 섹션 (A 섹션) 고른 후, 다른 섹션 (B 섹션) 을 골랐을 때, A, B 섹션이 비슷하면 된다.
Stochastic process
random variable 의 collection - X1,X2,X3 .. 가 있다고 하자. 이들이 각각 다른 모수를 가진 분포를 따를 때, 이를 stochastic process 라고 한다. stochastic process 의 반대개념은 deterministic process 이다. deterministic process 는 모든 step (t) 에 대해서 예측 가능하다. 예를 들어, 어떤 함수에 대한 미분함수는 특정 X 에서의 Y 값을 정확하게 알 수 있다. 이와 반대로 stochastic process 는 매 step 이 random 이기 때문에 어떤 확률 분포에서 왔다는 것만을 알 수 있을 뿐, 값을 정확하게 예측할 수 없다.
$$ X_t \sim distribution(\mu_t, \sigma_t) $$
예를 들어, 다음과 같은 시계열 데이터가 있다고 해보자.
$$ X_1 = 30, X_2 = 29, X_3 = 57 ... $$
시계열 데이터를 바라보는 한 가지 관점은 stochastic process 의 실현 (realization) 으로 보는것이다. 매 timestep 별로 어떤 확률 변수가 정해지고 우리는 그 확률변수에서 나온 하나의 샘플값을 관찰하는 것이다.
Autocovariance function
stationary time series 라는 가정을 하자. 두 가지 timestep s,t 에서의 covariance 를 정의해볼 수 있다. (확률 변수이기 때문)
$$ \gamma(s,t) = Cov(X_s, X_t) $$
$$ \gamma(s,s) = Var(X_s) $$
또한 아래처럼 covariance function 을 정의할 수 있는데, 이 함수는 stationary time series 라는 가정 하에 t 에 따라서는 값이 바뀌지 않으며, k가 결정하는 함수가 된다. (아래 식에서 c 는 추정값이다.) 이러한 time step (k) 에 따른 공분산의 식을 autocovariance function 이라고 한다.
$$ \gamma_k = \gamma(t, t+k) \sim c_k $$
즉, stationary time series 에서는 Cov(X1, X2) 나 Cov(X10,X11) 이나 기댓값은 같다고 할 수 있다. 그 이유는 데이터에서 두 가지 섹션을 선택했을 때, 그 모습이 똑같다고 기대하는것이 stationary time series 이기 때문이다.
또한 gamma(t_k, t) 는 autocovariance coefficient 라고 하며, stochastic process 에서의 실제 autocovariance 값이다. 데이터를 통해 구한 c_k 를 통해 autocovariance coefficient 를 추정한다.
Autocovariance coefficient
그러면 Autocovariance coefficient 의 추정값은 어떻게 구할까? timestep 을 k 라고 할 때, 추정값은 아래와 같다.
Scikit-learn Gradient Boosting 모델 예측값이 매번 달라지는 문제와 해결
아래 코드는 k-fold cross-validation 을 통해 best parameter 를 찾은 후, test set 에 대해 예측하는 코드이다. 이 코드에서 random_state=2020 을 지정하지 않으면, GridSearchCV 를 통해 구한 best parameters set이 매번 달라졌다. 즉 이말은 Gradient Boosting Tree 가 fitting 할 때마다 달라진다는 뜻이다.
Decision trees can be unstable because small variations in the data might result in a completely different tree being generated. This problem is mitigated by using decision trees within an ensemble.
The problem of learning an optimal decision tree is known to be NP-complete under several aspects of optimality and even for simple concepts. Consequently, practical decision-tree learning algorithms are based on heuristic algorithms such as the greedy algorithm where locally optimal decisions are made at each node. Such algorithms cannot guarantee to return the globally optimal decision tree. This can be mitigated by training multiple trees in an ensemble learner, where the features and samples are randomly sampled with replacement.
1. 우선 Decision tree 를 적합하는 방법은 heuristic algorithm (greedy algorithm) 이다. 왜냐하면 optimal 한 decision tree 를 찾는 것은 np-complete 문제이기 때문이다. 하지만 직접적인 문제는 아닌듯하다. greedy 한 방법으로 tree 를 만들더라도 매번 같은 greedy 한 방법을 이용하면 같은 tree 가 생성되기 때문이다.
2. Gradient Boosting 과 같은 ensemble 방법에서는 매 iteration 마다 subsample 을 만들어서 negative gradient 를 예측하는 모델을 만들어서 합치게 되는데 이 때, subsample 이 random 하게 설정되기 때문에 매 번 모형이 달라지고 이로 인해 예측 값이 조금씩 달라지게 된다.
정확한 원인이 무엇이든 Gradient boosting tree 를 만드는 것에는 randomness가 있으며 reproducible 한 코드를 작성하고 싶으면 GradientBoostingClassifier(random_state=2020) 와 같이 random_state 를 지정해야한다.
임상 정보 기반 위험도 평가부는 임상 정보와 유전체 정보에 따른 위험도를 산출하는 모듈로, 유전체/가족력 정보를 통해 대상자를 몇 가지 표현형 (phenotype) 으로 나눈 후, 각 표현형의 나이에 따른 유방암 발생 확률에 임상 정보를 통해 추정한 상대 위험도 (relative risk)를 곱하는 방법을 통해 위험도를 산출한다.
The clinical information-based risk assessment unit is a module that calculates the risk according to clinical information and genomic information. After dividing the subject into several phenotypes through genome / family history information, the risk of breast cancer according to the age of each phenotype and clinical It is calculated by the squared relative risk estimated from the information.
빠르게 영문 번역해야할 일이 있어 번역기의 도움을 받았는데 정말 좋은 것 같다. RNN seq to seq 의 개념에서 마침표를 하나의 단어로 인식한다면 기술적으로 불가능한것은 아니겠지만 어떻게 트레이닝을 했을지 정말 놀랍다.
이미지 인식 분야에서 각 label 의 이미지 수가 적을 때 이를 인식하고 분류하는 것은 challenging 합니다. 예를 들어 얼굴 인식 분야에서는 단 몇 장의 이미지만을 통해 동일인인지 여부를 구분해야하는 문제가 있습니다. 물론 augmentation 과 같은 방법으로 샘플 수를 늘려서 CNN 으로 multi-class classification 문제를 풀도록 학습시키는 방법이 가능합니다. 하지만 이 경우, 새로운 사람이 데이터 베이스에 추가되었을 때, 모델을 새로 학습해야한다는 문제가 생깁니다. 즉, 실시간 시스템에 적합하지 않은 방법입니다.
이러한 문제를 해결하는 한 가지 방법은 "Distance function" 을 이용하는 것입니다.
D(x_1, x_2) = degree of difference between images
Distance function 을 이용해, 예를 들어, D(Image1, Image2) <= k 인 경우 같은 사람이라고 예측하고, > k 인 경우 다른 사람이라고 예측할 수 있습니다. 또는 DB 에 있는 모든 Image 에 대해사 distance 를 계산한 후에 가장 distance 가 작은 사람으로 분류할 수 있습니다. 이러한 아이디어의 의미는 face recognition 에서는 누구인지 구분하는 것보다 "동일인지 여부" 가 중요하다는 것입니다. 또한 이를 이용해 multiclass classification 을 할 수도 있습니다. 이는 아이디어 측면에서 머신러닝의 고전적인 방법인 nearest neighbor 방법과 비슷합니다. 본 포스팅은 Distance function 의 인풋으로 넣기 위한 representation 을 만드는 함수 f 를 딥러닝으로 학습하는 방법에 관한 것입니다. 이미지의 distance 를 계산하기 위한 representation learning 개념입니다.
Siamese Network + Triple loss
Our approach is to build a trainable system that nonlinearly maps the raw images of faces to points in a low dimensional space so that the distance between these points is
small if the images belong to the same person and large otherwise. Learning the similarity metric is realized by training a network that consists of two identical convolutional
networks that share the same set of weights - a Siamese Architecture (Sumit Chopra, 2005, CVPR)
함수 f 를 딥러닝 방법을 통해 학습할 수 있는 한 가지 방법은 Siamese network 을 이용하는 것입니다. Siamese network 는 2005년에 CVPR 에 발표된 방법으로, weights 를 공유하는 두 개의 CNN 입니다. 이 CNN은 Image1과 Image2를 f(Image1) 과 f(Image2) 라는 vector representation 으로 변환시킵니다. 그리고 f 를 학습시키기 위해 loss function 을 정의하고, distance 를 나타낼 수 있는 representation 을 만드는 방향으로 weights가 학습됩니다. 이미지1과 이미지2의 distance 를 f(Image1)과 f(Image2)의 l2 norm 으로 정의해봅시다.
$$ D(x_1, x_2) = ||f(x_1) - f(x_2) || ^2 $$
loss function 으로 사용할 수 있는 한 가지는 Triplet loss 입니다. Triplet loss 는 3개의 이미지로부터 loss function 을 만드는 방법이며, 아이디어는 같은 사람의 이미지의 distance 가 다른 사람의 이미지의 distance 보다 작아지도록 하자는 것입니다. 이는 기술적으로 D(Anchor, Positive) 가 D(Anchor, Negative) 보다 작아지도록 잡자는 것입니다. 이 때, Anchor 와 Positive 는 같은 사람의 다른 이미지이고, Negative 는 Anchor, Positive 와 다른 사람입니다. 이 때, alpha 라는 margin 을 주어 충분한 차이가 벌어지도록 합니다.
실제 배치 트레이닝시 loss 는 아래와 같이 계산될 것입니다. m 은 배치 샘플 수입니다.
$$ J = \sum^{m}_{i=1} L(A^i, P^i, N^i) $$
Triplet loss 의 문제는, A, P, N 을 random 하게 골랐을 때, loss 가 0이 되는 것이 너무 쉽게 만족한다는 것입니다. 그래서 실제 트레이닝시 중요한 것은 구분하기 어려운 샘플을 고르는 것입니다. 즉, A-P 와 A-N의 distance 의 차이가 크지 않은 두 이미지를 우선적으로 사용하는 것이 좋습니다. 이 방법은 Triplet loss 를 제시한 논문에 설명되어 있습니다.
트레이닝 데이터에서 Triple loss 로 하나의 CNN 을 구현한 후 학습한 후, 테스트 데이터에서는 예를 들어, 이미지의 representation 을 얻은 후, DB 에 있는 representation 과의 distance가 k 미만일 때, 같은 사람이라고 verification 할 수 있습니다.
Siamese Network + Binary loss
아래와 같이 문제를 Binary classification 으로 formulation 해서 face recognition 을 구현할 수도 있습니다. 실제로 많이 사용하며, 성능도 괜찮은 방법입니다.
이 방법에서 Siamese Network 는 두 이미지를 input 으로 하고, 같은 사람을 1, 다른 사람을 0 로 encoding 된 label 을 통해 training 됩니다. triplet loss 를 사용한 방법에서는 max(l2 distance 의 차이+alpha, 0) 을 줄이는 방향으로 training 이 되었지만, binary classification 을 활용한 방법의 경우 구조가 약간다릅니다.
Siamese network와 binary classification 을 결합한 방법에서 CNN 이후 아키텍쳐는 다음과 같습니다.
1. 두 이미지에 대해 CNN 을 통과시켜 나온 두 representation 의 l1 vector 를 구합니다 (l1 vector는 CNN 으로 변환된 벡터의 absolute distance 를 원소로 갖는 vector 입니다).
2. l1 vector 를 hidden layer 에 통과시킨후 output layer 에서 sigmoid 변환을 합니다.
3. Binary cross entropy 를 loss function 으로 모델을 학습합니다.
4. 모델은 0-1 사이의 값을 갖는 output 내보냅니다. 이 값은 크면 클 수록 두 이미지가 비슷하다라는 것이므로 "similarity" 라고 할 수 있습니다.
5. 이 과정을 거치면 X1, X2 에 대한 CNN 의 output representation f(X1), f(X2) 는 같은 사람에 대해서 distance가 작게, 다른 사람에 대해서는 distance 가 크게 나오게 됩니다.
본 포스팅에서는 임상시험에서 층화 무작위배정 을 실제로 어떻게 하는지에 대해 알아보겠습니다.층화 무작위배정 은 공변량에 대해 층화하여 무작위 배정을 하는 방법입니다. 층화 무작위배정 을 하는 이유는 1) 해당 공변량 대해 Randomization 되어있도록 해서 bias 를 줄이고자 하는 것입니다. 이는 treatment/control group 간에 공변량의 분포가 다른 경우, bias 가 생기기 때문입니다. 하지만 공변량에 대해 treatment/control group 이 randomization 되어있다면, 해당 이론적으로는 공변량에 대해서는 분포가 다를 수 없어 이로 인한 bias 가 생기지 않게 됩니다. 2) 또한 공변량을 보정하면 공변량의 effect 를 제외하여 treatment effect size 의 참값을 더욱 잘 추정할 수 있습니다. 이를 통해 검정력을 증가시킬 수 있습니다.
다음과 같은 상황을 예로 들어 봅시다.
1. 총 4개의 기관이 임상 시험에 참여
2. 기관당 임상시험 참여자는 20명
3. 나이를 공변량으로 잡고 Block size 는 6,6,6,2 로 설정한다.
구체적으로 기관 별로 아래와 같은
- 20~30세 : 6명
- 30~40세 : 6명
- 40~50세 : 6명
- 50~60세 : 2명
4. treatment/control group 의 배정 비율은 1:1 이다.
즉, Block size가 6이면 treatment 3명, control 3명을 무작위 배정한다.
전략
1. 기관별로 층화 -> 똑같은 코드를 4번 돌리는 것으로 구현
2. 나이를 사이즈 6,6,6,2 로 층화 무작위 배정 -> for 문으로 구현
3. 블록별 무작위 배정을 위해 블록 별로 0~1사이의 난수를 발생하고 (이중 for 문으로 구현 ), 이 값을 기준으로 sorting 해서 중위수를 기준으로 두 그룹으로 나눈 후, A, B 약을 배정한다.
blockrand <- function(R, N, blocksize){
result <- data.frame(block=numeric(N), item=numeric(N), drug=character(N), rand=numeric(N), random_no=character(N), stringsAsFactors=FALSE)
index <-1for(i in c(1:ceiling(N/blocksize))){if(i ==(ceiling(N/blocksize))){
blocksize <- N - (i-1)*blocksize # 2
}for(j in c(1:blocksize)){
result[index,'block']<- i
result[index,'item']<- j
if(j <= blocksize/2){
result[index,'drug']<-'A'}else{
result[index,'drug']<-'B'}
result[index,'rand']<- runif(1)
index = index +1}}
result <- result[order(result$block, result$rand),]
result$random_no <- c(paste0(R,'-R',as.character(c(1:(ceiling(N/blocksize)*blocksize)))))return(result)}
inst1 <- blockrand('01',20,6)
inst2 <- blockrand('02',20,6)
inst3 <- blockrand('03',20,6)
inst4 <- blockrand('04',20,6)
이를 위하여 blockrand 라는 함수를 만듭니다. 이 함수는 기관명 R, 기관별 대상자 수 N, 블록 사이즈 blocksize 를 parameter 로 받아 결과 테이블을 dataframe 형식으로 생성하여 반환하는 함수입니다.
결과 예시
block itemdrugrand random_no
313 A 0.0332346301-R1
515B 0.2337787501-R2
111 A 0.5887212301-R3
414B 0.6491430001-R4
212 A 0.8629414001-R5
616B 0.8692321501-R6
822 A 0.0152988901-R7
923 A 0.1175475701-R8
1125B 0.1307349601-R9
1024B 0.4693400701-R10
721 A 0.5617163501-R11
1226B 0.6133922401-R12
1432 A 0.1135279601-R13
1331 A 0.6266774201-R14
1533 A 0.8225795901-R15
1836B 0.8591041801-R16
1735B 0.8799594401-R17
1634B 0.9277809501-R18
2042B 0.7082472801-R19
1941 A 0.7621264301-R20
이러한 층화 무작위배정은 머신러닝에서 특정 변수의 분포를 train/valid/test set 에서 맞추어줘서 모델의 일반화 성능을 보다 정확히 평가하고 싶은 경우에 사용되기도 합니다.