예를 들어, 우리의 친구 Justine 이 좋아할만한 소설을 예측하고 싶다고 가정하자. 현재 가지고 있는 정보는 "그녀가 최근 읽은 몇 가지 소설" 및 "그 소설들에 대해 그녀가 좋아했는지 안 좋아했는지 여부" 를 알고 있다.
표준적인 supervised machine learning 패러다임에서는positive example 과 negative example 들의 feature들을 비교하여, 새로운 소설 (unseen) 에 대해 그녀가 좋아할지 안좋아할지를 예측하는 모델을 만든다.
반면, semi-supervied paradigm 은 Justine 이 읽은 소설만 활용하는 것이 아니라 그녀가 읽지 않은 소설 (unlabeled) 까지 활용하여 그녀가 선호할만한 소설을 예측하는 시스템을 만든다. 당연히 전체 소설중, 그녀가 읽지 않은 소설이 훨씬 많을 것이며, 놀랍게도, 이를 활용하면 (unlabeled 데이터를 활용하면) 더욱 효율적인 시스템을 만들 수 있다는 것이다.
Why semi-supervised learning works?
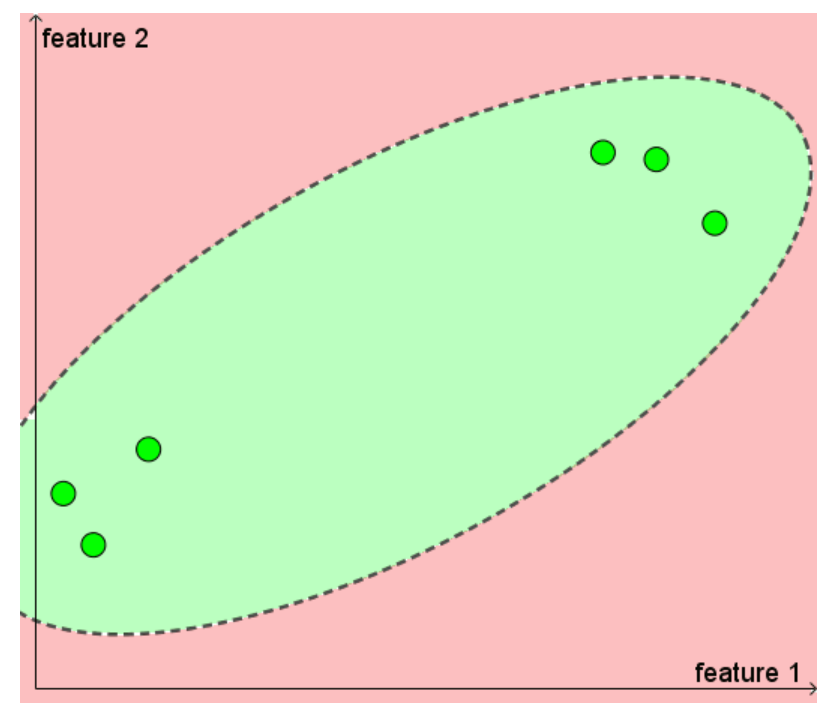
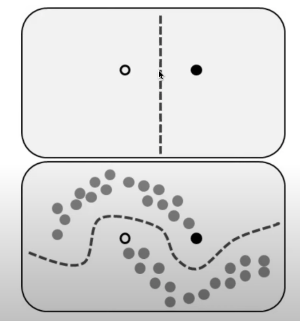
왜 unlabeld 데이터가 예측에 도움이 될 수 있는지를 이해하기 위해 위 그림을 보자.
초록색: positive cases
빨간색: negative cases
선: decision line
unlabeled 데이터를 활용하면 오른쪽 그림처럼 더욱 정교한 decision line 을 그릴 수 있다. 이를 통해 모델의 성능 및 일반화에 도움을 줄 수 있다.
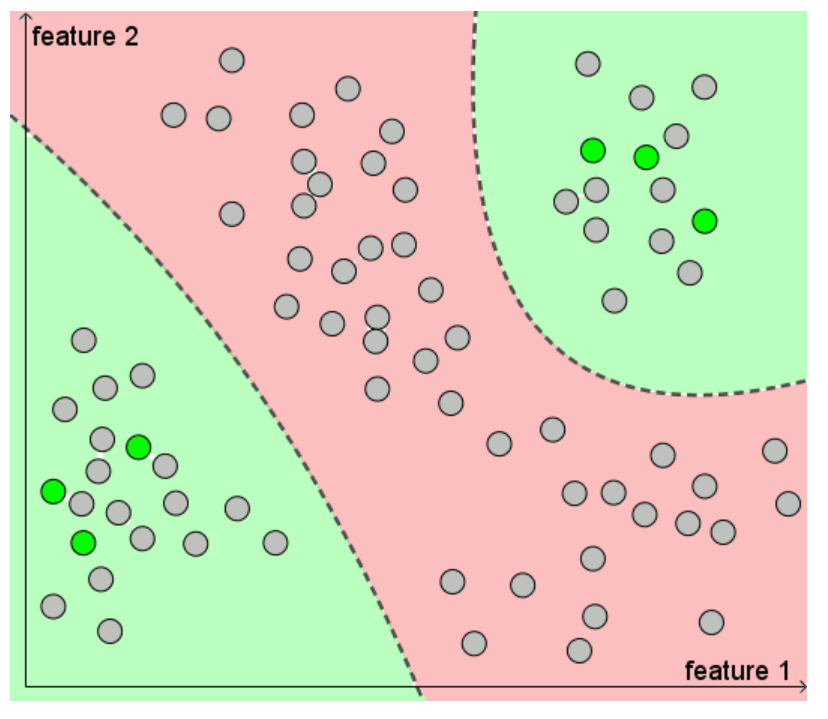
PU learning 의 직관적 이해
Positive-unlabeled learning 은 semi-supervised learning 은 한 가지 패러다임으로, positive case 와 unlabeld case 만 존재하는 문제에서, 사용할 수 있는 방법이다. 위 예시에서 Justine 이 좋아하는 소설에 대한 데이터만 갖고 있는 것이다. real-world 에서 이러한 상황은 생각보다 자주 존재한다. (항상 toy 문제처럼 positive case 와 negative case 가 잘 들어가 있지는 않다.)
초록색: positive cases
선: decision line
PU learning 이 왜 워킹 하는지에 대해 직관적으로 이해해보자.
1) 왼쪽 그림만을 보고, positive와 negative 를 구분하는 선을 만들라고 하면 어떻게 할 것인가? (머신러닝 모델이 아닌 사람의 직감으로) 다른 데이터들이 어떻게 놓여있는지를 알 수 없기 때문에, 타원 모양의 decision boundary 를 그리는 것이 한 가지 방법이 될 것이다.
2) 오른쪽 그림을 보고, 다시 positive 와 negative 를 구분하는 선을 만들라고 하면 어떻게 할 것인가? 왼쪽 그림과 비교하여 추가적인 정보 (unlabeled 데이터가 어디에 놓여있는지) 를 알고 있다. 그렇기 때문에 그림처럼 다른 decision boundary 를 그릴 수 있게 된다.
PU learning 의 몇 가지 테크닉들
1) Direct application of a standard classifier
가장 기본적인 접근 방법은 unlabeled case 를 negative 로 취급하고 분류 모델을 학습하는 것이다. 이 모델은 각 데이터 포인트에 점수를 주는데, positive case 에 대해서 평균적으로 더 높은 점수를 준다. 만약 unlabeled 데이터 중에 높은 점수를 받은 데이터 포인트가 있다면, positive case 일 확률이 높을 것이다.
이러한 '가장 나이브한 방식' 의 정당성은 이 논문에서 확인되었다 (2008년도). 이 논문의 주요 결과는, 몇 가지 특정한 가정하에, positive+unlabeled 데이터로 학습한 모델의 성능은 positive+negative 데이터로 학습한 결과와 비례한다는것이다.
저자의 코멘트에 따르면, 이 의미는 다음과 같다: "모델이 잘 학습되었다고 가정하면, PU 모델은 어떤 데이터 포인트가 positive 에 속할 가능성에 대한 순위를 매기는데 활용할 수 있다."
2) PU bagging
더욱 정교한 접근 방법은 bagging 의 변형을 활용하는 것이다.
- positive data 와 함께 "unlabeled data 로 부터 random sampling 한 데이터(with replacement)" 를 같이 활용한다.
- 위 boostrap sample 을 negative 로 하여 모델을 학습한다.
- out of bag 샘플 (boostrap sample 에 포함되지 않은 unlabled data) 에 대해 스코어를 매기고, 저장한다.
- 이러한 방법을 반복적으로 적용하고, unlabeled 데이터들에 대해 나온 스코어들을 평균낸다.
이러한 접근 방법이 소개된 논문 (2013년) 에서 저자들은 특히, 갖고 있는 positive sample 숫자가 적고, unlabeled 데이터 중, negative 의 비율이 적은 PU learning 상황에서 state-of-the-art 성능을 달성했다고 주장했다 (2013년도 기준). 또한 unlabeled 데이터의 규모가 큰 경우, 이러한 bagging 방식은 더 빠르게 모델을 학습할 수 있다.
3) Two-step approaches
많은 PU learning 전략은 two-step 접근 방법 카테고리에 속한다. (이 방법이 소개된 논문 (2014년))
Step1 - unlabeled 중에 negative 인 것이 가장 확실한 포인트들을 찾는다. (이를 reliable negative 라고 한다.)
Step2 - positive 와 reliable negative 로 모델을 학습하고, 나머지 unlabeled 데이터에 적용한다.
일반적으로 Step2 의 결과를 통해 Step1 으로 되돌아가서, reliable negative 를 찾고 이를 반복하게 된다. 당연히 reliable negative 의 규모가 충분히 크고, 실제 negative 를 많이 포함하고 있을 수록 더 좋은 모델을 구축할 수 있다. 얼마나 반복해서 적절한 수의 reliable negative 를 찾을 수 있을지가 핵심적인 부분이라고 할 수 있다.
* 이 포스트는 Mit technology review 의 22년 6월 28일 아티클 "AI's progress isn't the same as creating human intelligence in machines " 개인의 의견을 담아 리뷰한 글입니다.
제목에서 알 수 있듯 위 아티클은 AI 의 발전은 기계로 인간 지능을 창조하는 것과 동일하지 않다. 고 말하고 있다.
AI 의 두 분야
1. 인간의 지능을 컴퓨터에 구현하는 것 (Scientific AI)
2. 엄청난 양의 데이터를 모델링하는 것 (Data-centric AI)
두 분야는 매우 다르다. 두 분야의 개념 차이만큼이나 두 분야의 야망과 최근 발전 상황이 다르다고 할 수 있다.
이 기사의 요지중 하나는 최근 AI 분야의 발전은 대부분 Data-centric AI 에서 이루어졌다는 것이다.
1) Scientific AI
인간 수준의 지능을 컴퓨터에 구현하기 위한 분야를 말하며, 1950년대부터 수십년간 이어져온 과학의 매우 심오하고 도전적인 과제라고 할 수 있다. 최근 컴퓨터에 구현된 인간 수준의 지능과 관련하여 Artificial general intelligence (AGI) 라는 용어를 많이 사용한다.
2) Data-centric AI
1970년 현대와 비교하면 비교적 간단한 “decision trees” 모델을 만드는 것으로부터 시작되었으며, 최근에는 흔히 '딥러닝' 으로 일컫는 신경망 모델의 발전으로 큰 유명세를 얻고 있는 분야이다. Data-centric AI 는 “narrow AI” 또는 “weak AI" 라고도 불리지만, 최근 다양한 분야에서 여러 잠재력을 보여주었다.
수많은 양의 학습 데이터와 컴퓨팅 파워가 결합된 딥러닝 모델은, 음성인식, 게임 등 다양한 분야의 "narrow tasks" 에 적용되어 왔다. AI 기반의 예측 모델은 수많은 반복 훈련을 통해 점점 정확도가 높은 모델을 만들어 내고 있다. AI 분야의 bottle neck 은 사람이 labeling 한 학습용 데이터가 필요하다는 것인데, 최근 AI 가 가상의 labeled 데이터를 만들어내는 분야도 크게 발전하고 있다.
GPT-3 는 언어 모델은 OpenAI 에 2020년에 발표한 모델로 이러한' 학습용 데이터 생성' 분야의 잠재력을 보여주었다. GPT-3 은 수십억개의 문장을 통해 학습되었으며, 그럴듯한 문장을 자동으로 만들어낸다. 또한 질문에 대해 정말로 사람이 쓸법한 문장으로 적절한 답을 하기도 한다.
GPT-3 모델을 활용하고 있는 어플리케이션 예시 (분야별)
GPT-3 데모사이트 에는 다양한 분야의 GPT-3 open API 를 활용한 다양한 어플리케이션들의 리스트를 확인할 수 있다.
2)할루시네이션: GPT-3 한테 1492년에 미국 대통령이 누구냐고 물으면 기쁘게 답변한다.
(실제로 1492년은 콜롬버스가 신대륙을 발견한 때로 미국 대통령은 존재하지 않았다.)
3) 높은 비용: 학습하는데 수많은 양의 데이터가 필요하고, 레이블이 있는 학습데이터는 비싸므로, 높은 비용이 요구되는 모델이다.
4)불투명성: 왜 GPT-3 가 그런 결론을 냈는지에 대해 종종 이해하기 어려울 때가 있다.
5)학습데이터 편향: GPT-3 는 학습 데이터를 흉내낸다. 학습 데이터는 웹으로부터 많이 수집되기 때문에 "toxic content" 가 많이 포함되어 있다. (sexism, racism, xenophobia 등등..)
요약하자면, GPT-3 는 신뢰하기 어려울 때가 많다. 즉, 인간 수준의 지능을 가지고 있는 것은 아니다.
이러한 한계점에도 불구하고 연구자들은 GPT-3 의 multi-modal versions 을 연구하고 있고 (multi-modal 이란 커뮤니케이션 채널이 여러개라는 의미이다.), 그 중 하나가 DALL-E2 와 같은 모델이다. DALL-E2 는 자연어를 인풋으로 받아, 실제적인 이미지를 생성하는 모델이다. GPT-3 는 인풋으로 텍스트를 받아 텍스트를 아웃풋으로 보여주는 모델이라면, DALL-E2 는 인풋으로 텍스트를 받아 이미지를 아웃풋으로 보여준다.
DALL-E2: 'an astronaut lounging int a tropical resort in space' 라를 문장을 vaporwave 스타일로 생성한 이미지이다.
AI 개발자들은 이러한 DALL-E2 모델을 로봇, 생명과학, 화학 등 다양한 분야에 어떻게 적용할 수 있을지를 고민하고 있다.
Data-centric AI 의 한계점중 하나는 이러한 시스템들이 인간에 의해 만들어진다는 것이다. 어떠한 문제를 formulation 하고, 이를 해결하는 시스템을 설계하고 만드는 것은 인간이다. 피카소의 유명한 말이 있다.
“Computers are useless. They only give you answers.”
기술을 기반으로한 인간의 발전은 좋은 질문을 던지는 것에서부터 오는 경우가 많다고 생각한다. 예를 들어, 자율 주행차를 생각해보면, "자동차 운전 조작을 자동화할 수 있지 않을까?" 라는 질문에서 시작됐을 것이다. 이러한 질문을 해결하기 위한 방법을 공학적으로 설계하고, 여기에 AI 기술을 활용하여 "자율 주행차" 가 세상에 나올 수 있었을 것이다.
현재의 AI 는 질문에 대한 좋은 답을 줄 수 있지만, 새롭고 창의적인 질문을 던지거나, 해결 방법을 설계하지는 못한다. AI 가 "자동차 운전의 자동화" 를 생각하고, 이를 어떻게 구현할지 제시하지는 못하는 것처럼 말이다. 아직까지 컴퓨터는 답을 줄 뿐, 질문을 만들지는 못한다.
AI 시스템이 좋은 질문을 만들게 될 날이 오는 것을 기대할 것이다. 먼 훗날이 될 수 있겠지만 그 날이 오면, 오래된 과학의 도전적인 과제 중 하나인 인간 수준의 지능을 이해하고 구현하는 것에 대하여 해결의 실마리를 찾을 수 있을지도 모른다.
R 에서 난수를 생성 또는 랜덤 샘플링 작업의 결과가 일별로 바뀌도록 하고 싶을 때가 있다.
방법은 간단하게 일별로 random seed 를 동일하게 맞춰주면 된다.
특정 날짜 '01/06/2022' 를 integer 형으로 변환하면 일별로 동일한 숫자가 나오도록 구현할 수 있다.
library(tidyverse)
dayYear <- as.Date(Sys.Date(),format='%d/%m/%Y') %>% lubridate::yday() %>% as.integer()
set.seed(dayYear)
sample(nrow(10)) # 같은 날에는 동일한 순서의 숫자 10개가 나온다.
주의할점은 값이 정수를 갖도록 as.integer 함수를 통해 변환해주어야한다.
(만약 double 인 경우, 실제 시드는 매번 달라진다. 이는 컴퓨터가 double 형을 메모리에 저장하는 방식 때문일듯하다.)
최근 다양한 도메인에서 머신러닝이 활용되고 있다. 머신러닝의 문제점은 training data 가 필요하다는 것이다.
현실에서는 label 이 있는 데이터를 수집하기 어렵거나 높은 비용이 요구되는 상황이 많다.
semi-supervised learning 이러한 상황에서 전체 데이터의 일부에만 label 이 있을 때 사용한다.
왜할까?
semi-supervised learning 의 핵심 과정 중 하나는 unlabled data 를 labled data 로 변환하는 것이다. (이를 pseudo-labeling 이라고 한다.) 그런데, 전체 데이터의 일부에 lable 이 있다고 하면, 그 데이터를 training 데이터로 모델을 만들면 안 되는가?
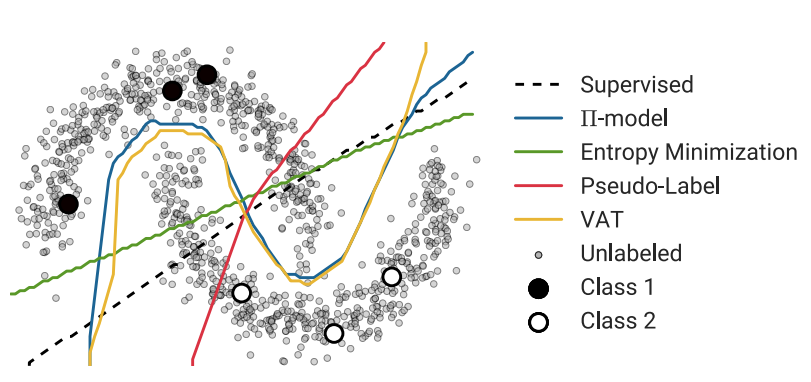
위 그림을 보면, 소수의 labeled data 로 만든 decision boundary 보다 unlabled data 를 사용한 것이 더 세밀하다는 것을 직관적으로 알 수 있다. 즉, 더 많은 데이터들에 대한 generalization 이 잘 된다는 것이다.
semi-supervised learning 의 이점
labled data 와 unlabled data 를 combine 하는 것은 accuracy 를 상승시킨다. (may be due to generalization)
unlabled data 를 획득하는 것은 상대적으로 cheap 하다. -> 잘만 되면 더 비용효율적이다.
다양한 SSL 방법론에 따른 decision boundaries
semi-supervised learning 의 가정
1) Continuity / smoothness assumption
"다차원 공간 상에서 가까운 거리에 있는 샘플들은 labeld 이 아마 같을 것이다." 라는 가정이다. 이는 지도학습에서도 마찬가지로 있는 가정이다. 다만 semi-supervised learning 에서는 가까운 거리에 있는 샘플들은 예외 없이 같은 label 이 된다. 라는 점이 다르다.
2) Cluster assumption
"데이터는 클러스터를 형성할 것이며, 같은 클러스터에 속한 샘플은 같은 label 을 공유할 가능성이 높다"라는 가정이다. (같은 label 을 가진 샘플들이 다양한 클러스터에 존재할 수는 있다.) 이는 clustering 알고리즘에서의 smoothness assumption 으로 볼 수 있다.
3) Manifold assumption
"고차원 공간의 데이터를 저차원 공간에 표현할 수 있다." 라는 가정이다. 이는 모델링에서는 당연한 가정이라고 볼 수 있다. 예를 들어, 수많은 피쳐 x 를 통해 하나의 y를 예측하는 과정이니 말이다. manifold assumption 성립하지 않으면 예측이 불가능하다고 볼 수 있다.
pseudo-labeling
labeled data 를 통해 unlabled data 를 labled data 로 변환하는 것을 말한다.
Active Learning
labeled data 를 주어진대로만 사용하지 않고, 재구성하는 전략을 말한다.
가장 성능을 높이는데 효과적인 샘플 (labeled or unlabeld) 에 대해 labeling 을 수행하는 전략이다.
supervised learning 에서 학습이 잘되는 일부 labeling data 만 사용할 수 있다.
semi-supervised learning 에서 pseudo-labeling 하는 것도 active learning 의 일종이다.
Margin sampling
margin sampling 은 active learning 의 예시로 decision boundary 를 효율적으로 찾는 방법중 하나로 가장 애매한 (uncertain) 샘플을 labeled data 로 변환해 나가면서 decision boundary 를 업데이트 해나가는 방법이다. 아래와 같이 random 하게 업데이트 하는 것보다 빠르게 클래스를 잘 분류할 수 있는 boundary 를 찾을 수 있다.
Weak supervision
ground truth label 이 없을 때, subject matter expert (SME) 가 휴리스틱한 방법으로 labeling 하는 것을 말한다.
만약 이 방법으로 어떤 샘플이 A 레이블에 할당되었다고 하더라도, 실제로는 A 레이블이 아닐 가능성을 갖고 있다.
이를 noisy label 이라고 한다.
Snorkel
스탠포드에서 2016년에 개발되었다. manual labeling 을 줄이는 방법으로 training data 를 구축하기위한 라이브러리이다. snokel 은 weak supervision 상황을 해결하는 것을 돕는다.
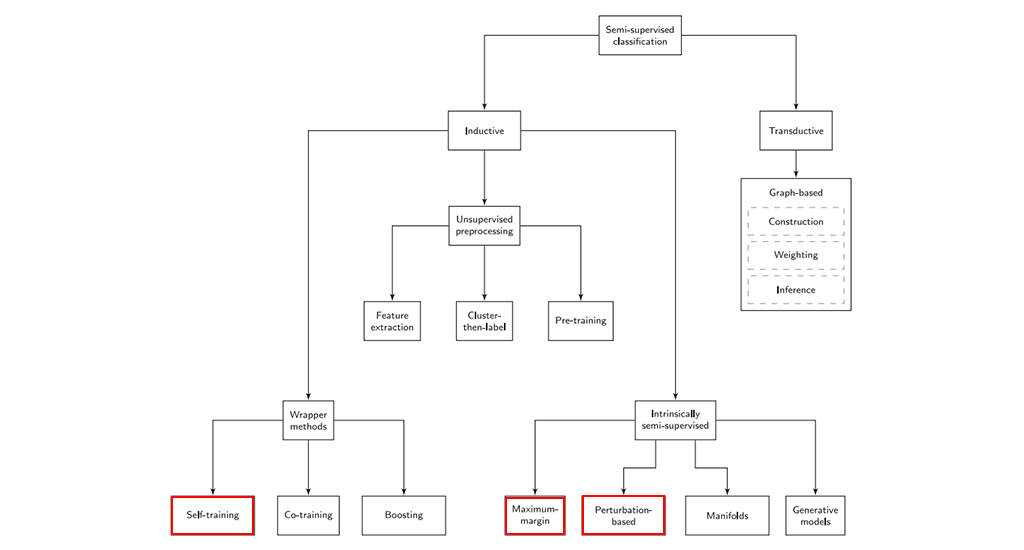
semi-supervised learning 의 분야
semi-supervised learning 의 핵심과정인 pseudo-labeling 을 어떻게 수행할 것인가?
단순히 model prediction 을 통해 pseudo-labeling 을 하는 것보다 성능이 좋은 다양한 방법론들이 존재한다.
위 분류에서는 semi-supervised learning 을 크게 transductive 와 inductive로 나눈다. [1]
ㄴ transductive 와 inductive 의 차이를 데이터 과점에서 본 포스팅 (link)
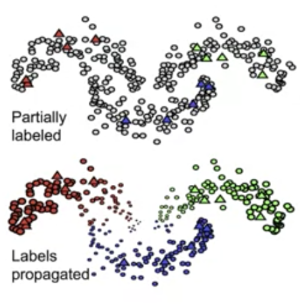
참고자료 [2] 에서는 1) graph-based 방법과 2) consistency-based 방법으로 나누기도했다. Graph-based method은 대표적으로 Label propagation 방법이 있다. consitency-based method 는 최근 각광받고 있는 방법으로 Mixmatch 를 예로 들 수 있다.
참고자료
[1] Van Engelen, Jesper E., and Holger H. Hoos. "A survey on semi-supervised learning." Machine Learning 109.2 (2020): 373-440
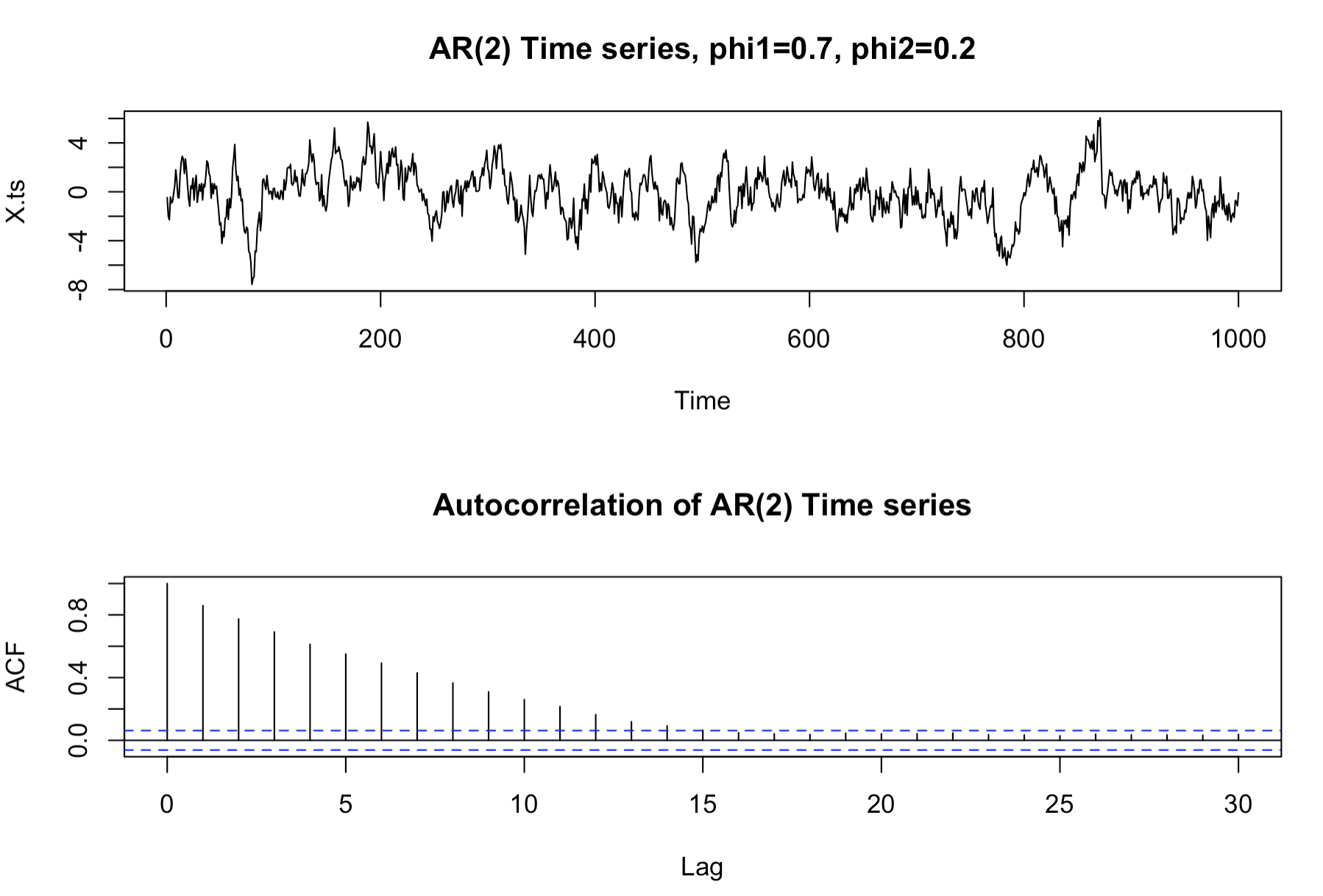
p=2 이고, 가중치가 0.7, 0.2 인 autoregressive process 는 아래와 같다.
$$ X_t = Z_t + 0.7X_{t-1} + 0.2X_{t-2} $$
이를 R 코드로 구현하면 아래와 같다. 선차트를 통해 보면 현재 값이 과거 값과 높은 상관성이 있다는것을 확인할 수 있다. correlogram 을 통해 가까운 시간에 측정된 값이 현재값과 더 높은 상관성이 있다는것을 확인할 수 있다. (가중치가 0.7, 0.2 이므로)
set.seed(2017)
X.ts <- arima.sim(list(ar=c(0.7,0.2)), n=1000)
par(mfrow=c(2,1))
plot(X.ts, main="AR(2) Time series, phi1=0.7, phi2=0.2")
X.acf <- acf(X.ts, main="Autocorrelation of AR(2) Time series")
X.acf
Moving average process 와의 관계
Autoregressive process 는 moving average process 의 무한 수열로 나타낼 수 있다.
차수 (p) 가 1인 AR 을 생각해보자.
아래와 같이 식을 쓸 수 있다. (Z는 평균이 0, 분산이 sigma^2 을 따른다고 가정하고, phi 를 theta 로 치환하자.)
위 AR(1) process 에서 Z 를 제외한 나머지 텀들을 한쪽으로 옮겨서 아래와 같은 식을 만들 수 있다.
$$ \phi(B) = 1-\phi B $$
이 때, 우변을 0으로 만드는 B 의 해를 찾는다. 해는 B = 1/phi 이다. B 의 해가 단위원 (unit circle) 바깥에 있는 것이 stationarity 를 만족하기 위한 조건이 된다. 따라서 AR(1) 모델에서는 phi 의 절댓값이 1 미만이어야 stationarity 를 만족한다.
따라서 Random walk model 의 시간에 따른 평균은 t*mu 이고, 분산은 t*sigma^2 이다. 만약 Z의 평균이 0이라고 가정하더라도 분산이 시간에 따라 점점 커진다는 것을 알 수 있다. 따라서 Random walk model 은 stationarity 를 만족하지 않는다.
moving average 의 parameter q 와 가중치 theta 를 고정해놓고 계산을 하면, 평균과 분산은 t 와는 관계 없이 고정된다는 것을 알 수 있다. 따라서 moving average model 은 stationarity 를 만족한다.
추가적으로 Moving average model 의 auto covariance function 을 구해보자.
moving average model 은 stationarity 를 만족하기 때문에 auto covariance function 은 time spacing 에만 의존한다. 또한 이전 포스팅에서 time spacing 이 최대 q 인 경우에만 자기상관성이 존재한다는 것을 correlogram 을 통해 확인할 수 있었다. moving average model 의 노이즈의 평균이 0일 때를 가정하고 covaraicne 를 구해보자.
특정 시점 t에서의 주가를 X_t 라고하자. 또한 특정 시점 t 에서의 회사의 공지 Z_t (noise) 가 주가에 영향을 미친다고 하자. 그런데 과거 시점 (t-1, t-2...) 에 회사의 공지도 주가에 영향을 미친다. 이런 경우에 X_t 를 다음과 같이 모델링할 수 있다.
# noise 생성
noise <-rnorm(10000)
ma_2 = NULL
# ma(2) 생성을 위한 loop
for (i in 3:10000) {
ma_2[i] = noise[i] + 0.7*noise[i-1]+0.2*noise[i-2]
}
# shift
moving_average_process <- ma_2[3:10000]
moving_average_process <- ts(moving_average_process)
par(mfrow=c(2,1))
plot(moving_average_process, main = "A moving average process of order 2", ylab = "")
acf(moving_average_process, main = "Correlogram of ma (2)", ylab = "")
correlogram 을 보면 time step 이 0,1,2 인 경우에만 상관성이 있는 것을 확인할 수 있다. 우선, time step 이 0 인 경우는 항상 auto correlation coef 1이다. 또한 현재값에는 최대 2 time step 전의 noise 까지 반영이 되기 때문에, 최대 2 time step 의 값과 상관성이 있다는 것을 확인할 수 있따.
아래와 같이 정의되는 X_t 를 random walk 이라고 한다. X_t 는 이전 time step 에서의 값 X_t-1 에 noise Z가 더해진 값이다. random sampling 과 다른점은 현재값이 이전값에 더해진다는것이다. 이는 랜덤하게 어떤 한 방향으로 걷는것과 비슷하다. 매번 시작점에서 한발짝 걷는 것이 아니라 한발짝 걸어서 도착한 곳에서 다시 한발짝을 간다.
$$ X_t = X_{t-1} + Z_t $$
$$ Z_t \sim Normal(\mu, \sigma) $$
이러한 random walk 모델에서 X_t 는 이전 time step 에서의 값 X_t-1 과 매우 큰 연관성을 갖는다. 따라서 non-stationary time series 데이터이다.
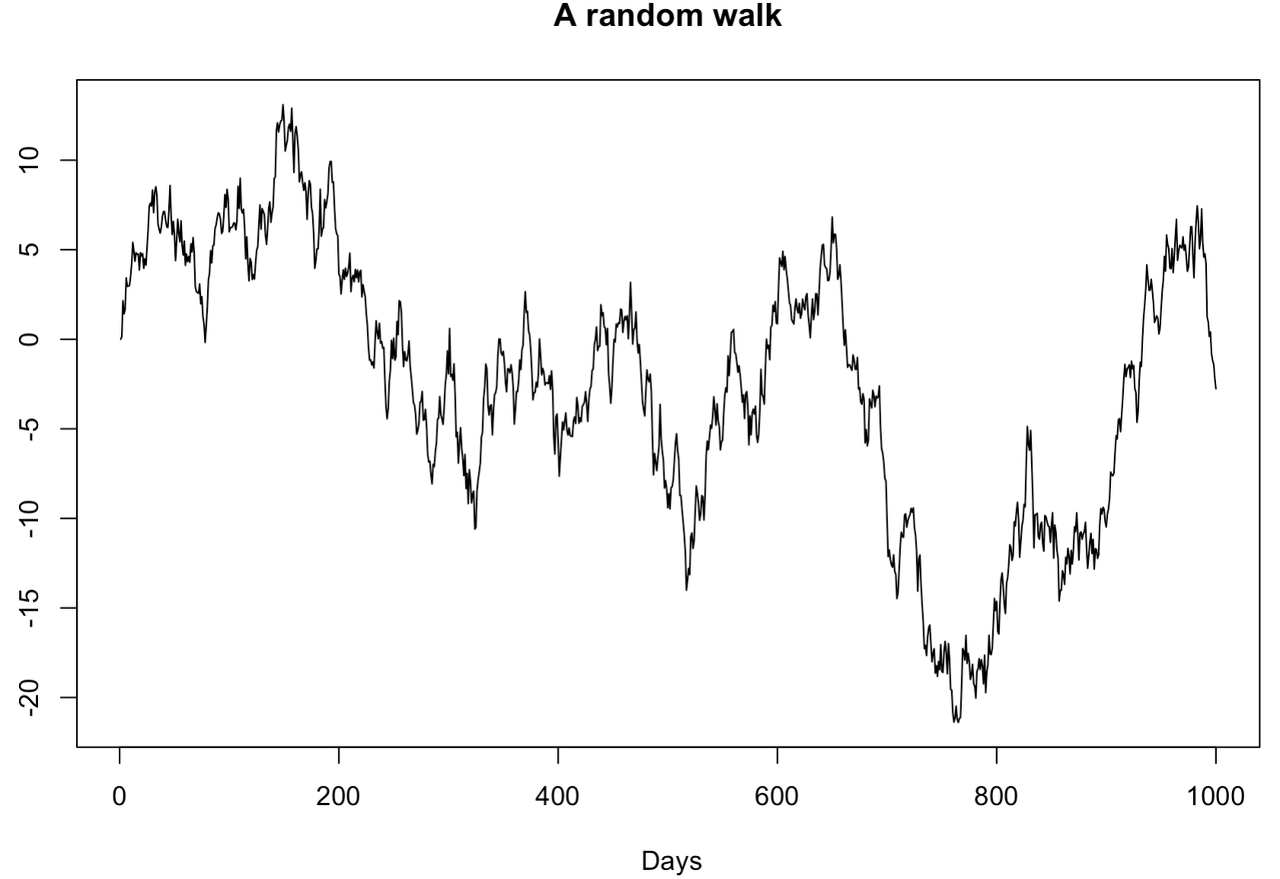
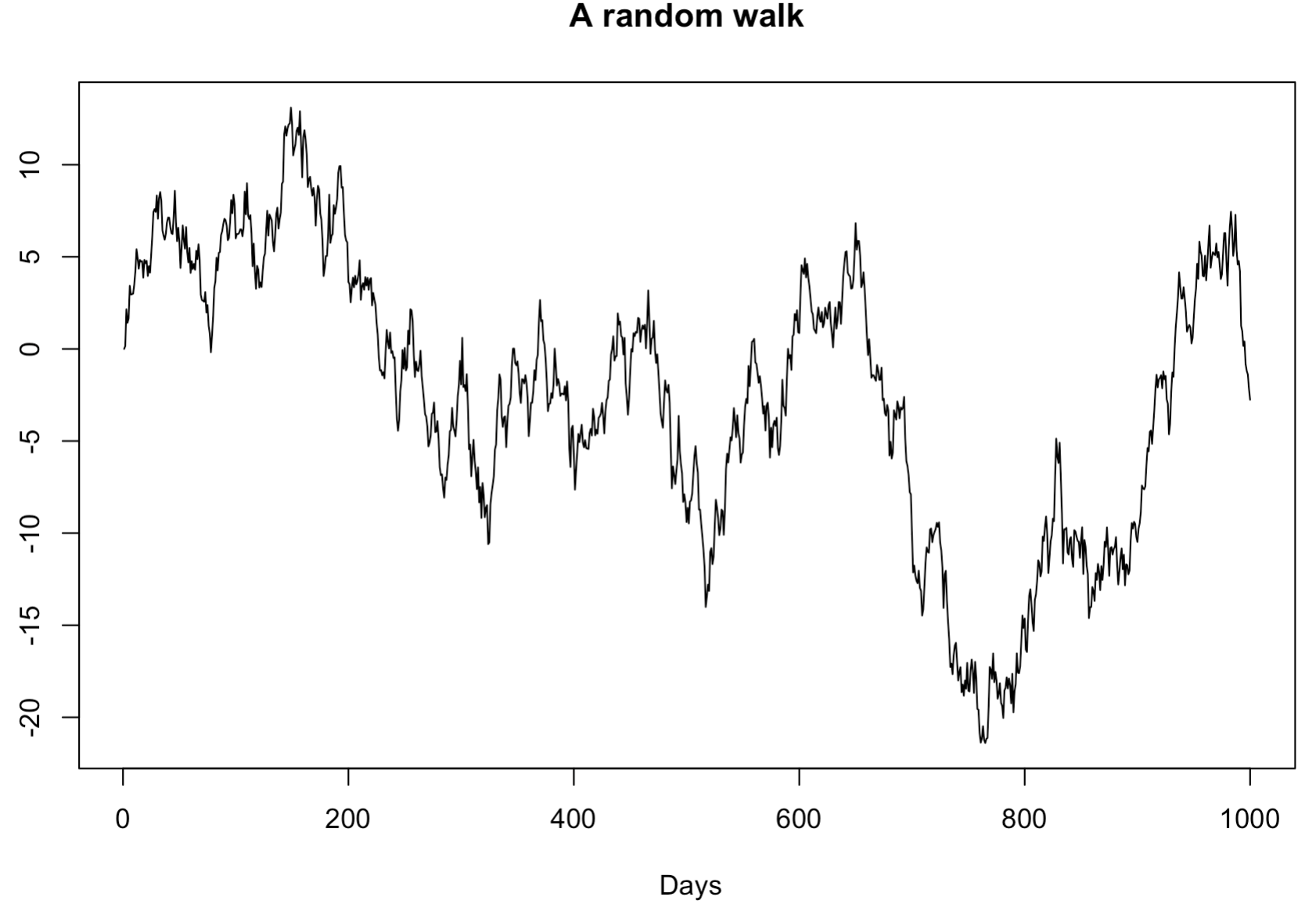
Random walk model simulation in R
R 로 random walk 모델을 만들어보자. 아래는 1000개의 random walk 데이터를 생성하는 예제이다. 시계열 그래프를 그려보면, 이 데이터는 non-stationary time series데이터라는 것을 확인할 수 있다. 구간을 나눠서보면 트렌드를 보이기 때문이다.
x <- NULL
x[1] <- 0
for(i in 2:1000){
x[i] <- x[i-1]+rnorm(1)
}
random_walk <- ts(x)
plot(random_walk, main="A random walk", ylab="", xlab=" Days", col="black")
위 그림은 전형적인 random walk 그래프이다.
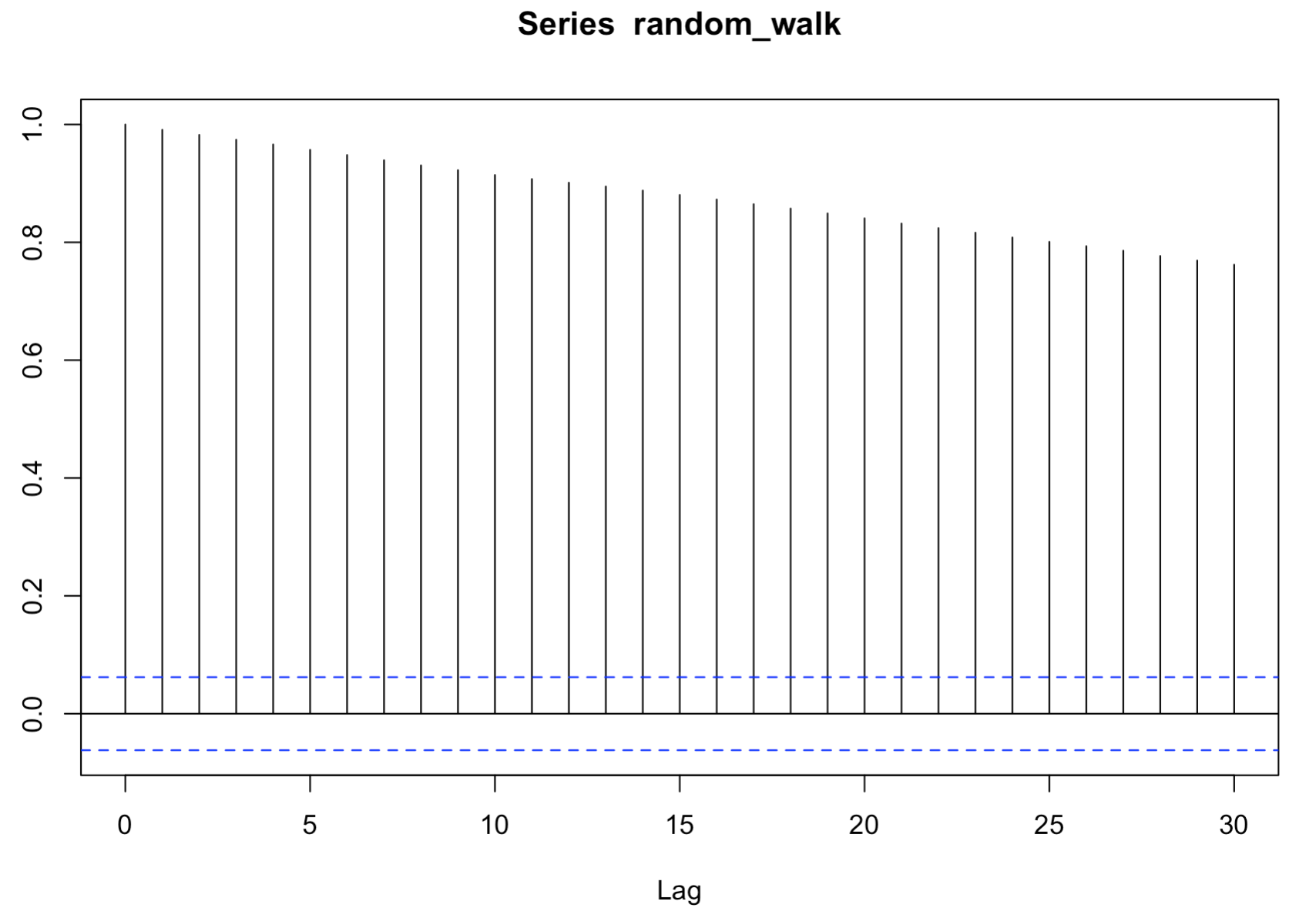
random walk 데이터에서 correlogram 을 그려보자. 인접한 time step 에서 auto correlation coefficient 가 큰 패턴을 보이기 때문에 non-stationary time series 라는 것을 다시 확인할 수 있다.
acf_result <- acf(random_walk)
random walk 모델에서 noise Z는 stationary time series 라고 볼 수 있다.
$$ Z_t \sim Normal(\mu, \sigma) $$
noise 가 stationary time series 라는 것을 데이터로 실제로 확인해보자.
random_walk_diff <- diff(random_walk)
plot(random_walk_diff, main="A random walk diff", ylab="", xlab=" Days", col="black")