R studio server 환경에서 sparklyr 세팅
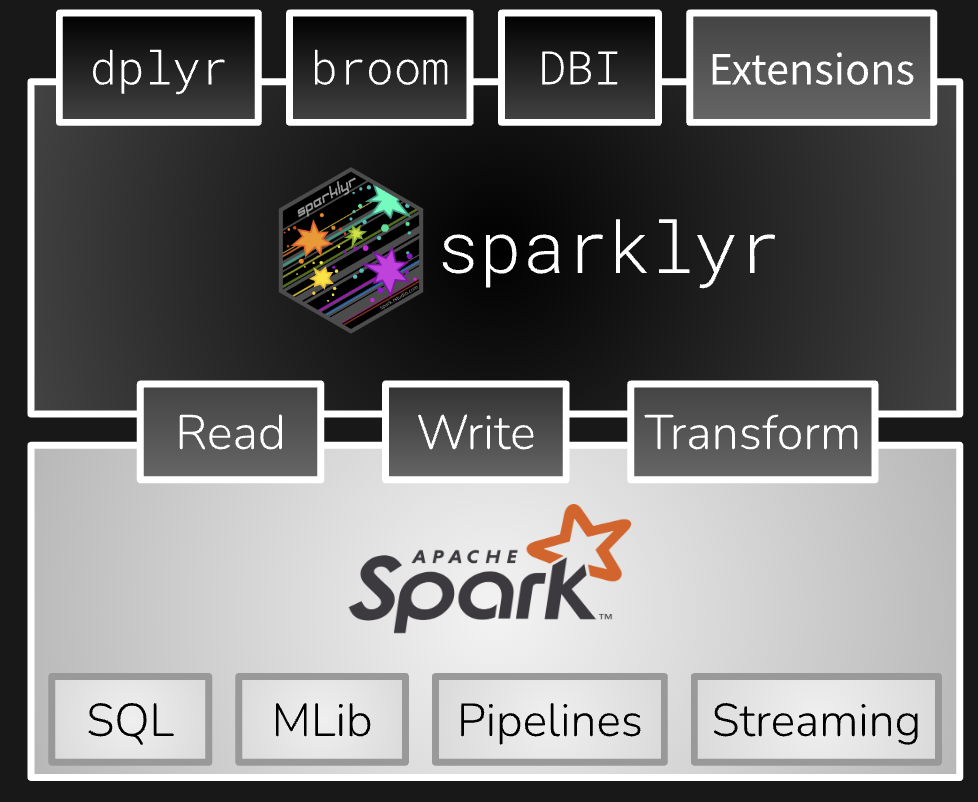
sparklyr 는 spark 위에서 동작하는 r library 이다. R 은 문법이 분석에 최적화 되어있고, 시각화가 강력하다는 장점이 있지만, in-memory 시스템이기 때문에 서버 또는 PC 의 메모리가 작으면 큰 데이터를 읽을 수 없다는 치명적인 단점이 있다. 이를 보완해줄 수 있는 것이 sparklyr 이다.
비지니스 분석에서 유저 데이터는 우선 샘플 사이즈가 크고, 다양한 피쳐를 붙여서 분석하는 경우가 많아, 서버 메모리에 올리기 부담스러운 경우가 많다. 물론 같은 목적으로 pyspark 도 많이 사용하지만, R 이 익숙한 사람에게는 sparklyr 도 좋은 옵션일듯하다. sparklyr 은 sparkly + R 의 합성어인것처럼 보인다. R 에서 spark 를 사용하는 방법은 SparkR 또는 sparklyr 을 사용하는 방법이 있는데, sparklyr 이 좀 더 인기가 있는듯하다. 그 이유는 dplyr 문법을 그대로 활용할 수 있기 때문에 쉽기 때문이다 (이건 S4 객체를 이용해 sparklyr 에서 spark dataframe 객체에 dplyr 함수가 적용될 때의 액션을 wrapping 해 놓았기 때문이다). sparklyr 의 동작 방식은 dplyr operation 을 sql 로 변환해서 spark 로 실행한 후 결과값을 리턴 받는 형식이다.
R studio server 환경에서 sparklyr 을 사용할 때 주의할 점은 환경이 유저별로 분리되어 있다는 점이다. jupyter notebook 의 경우, root 권한으로 실행하면, root 권한을 이용할 수 있으며, 기존의 환경 변수 (environment variable)를 그대로 이용할 수 있다. 그런데 R studio server 는 서버 자체의 환경변수가 유지되지 않는 경우가 많다. 따라서 이러한 경우에는 환경변수를 직접 지정해주는 것이 필요하다. sparklyr 에서 필요한 환경 변수는 아래와 같다. JAVA, Spark 에 대한 HOME 환경 변수 경로를 기본적으로 요구한다. Spark 는 scala 로 작성되어 있지만, 자바가상머신(JVM) 위에서 작동하기 때문이다.
HADOOP 관련 path 가 필요한 이유는 Spark 가 원격 hdfs 에서 작동하도록 세팅되었기 때문이다. spark 는 local 에서 데이터 작업을 할 수도 있고, 외부 저장소에서 데이터 작업을 할 수 있다. 본 포스팅에서는 local 데이터를 읽어오는 게 아니라 원격 하둡에 저장 되어 있는 hive 테이블에서 sql 로 데이터를 읽어올 것이다. 만약 회사에서 분석하는 경우, 원격 하둡이나 hive 연결에 대한 세팅을 데이터 엔지니어링 부서에서 담당하고 있는 경우가 많을 것이다. 따라서 해당 부분에 관련된 설명은 포함하지 않았다. spark 세팅이 완료 되었다면, 간단하게 sdf_sql 함수를 이용해 sql 을 통해 하이브 테이블을 spark dataframe 객체로 데이터를 읽어오기만 하면 된다.
만약 spark job 제출시에 local 리소스를 사용하는 것이 아니라, cluster 모드로 동작하려면 master='yarn-cluster' 로 지정하고, config 파라미터를 지정하여 넘겨준다. 본 포스팅에서는 local 모드로 작성하였다.
spark connection 잡고 hive table 읽어오기
library(sparklyr)
library(tidyverse)
Sys.setenv(JAVA_HOME="/usr/java/default")
Sys.setenv(SPARK_HOME = '/hadoop/spark3')
Sys.setenv(HADOOP_HOME="/hadoop/hadoop")
Sys.setenv(YARN_CONF_DIR = '/hadoop/conf/hadoop')
Sys.setenv(PATH = "/root/utils/miniconda3/envs/default/bin:/root/utils/miniconda3/bin:/usr/java/default/bin:/usr/local/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/hadoop/hive/bin:/hadoop/hadoop/bin:/hadoop/sqoop/bin:/hadoop/spark/bin:/hadoop/spark3/bin:/hadoop/trino/bin")
sc <- spark_connect(master = "local", app_name = "sparklyr")
### yarn-cluster 를 사용하는 경우 ###
# config <- spark_config()
# config$`sparklyr.connect.timeout` <- 600
# config$`sparklyr.yarn.cluster.hostaddress.timeout` <- 600
# config$`spark.executor.memory` <- "32g"
# config$`spark.executor.cores` <- "16"
# sc <- spark_connect(master = "yarn-cluster", app_name = "sparklyr", config=config)
df <- sdf_sql(sc, "SELECT * FROM table where date_id = '2024-05-31'")
df %>% head
df %>% group_by(date_id) %>%
summarize(n=n(), session_cnt = n_distinct(session_key), user_cnt = n_distinct(id))
# Source: SQL [?? x 4]
# Database: spark_connection
date_id n session_cnt user_cnt
<chr> <dbl> <dbl> <dbl>
1 2024-05-20 4323859 646492 559531
2 2024-05-01 4204694 605267 517271
3 2024-05-02 4092809 599786 522737
4 2024-05-07 3917828 562908 493482
5 2024-05-03 4285870 647084 552651
6 2024-05-06 3727415 518329 453484
7 2024-05-28 3682164 555470 493450
8 2024-05-10 4227072 643118 567372
9 2024-05-12 3372529 478201 420199
10 2024-05-17 3832487 587830 521759
HDFS 로 데이터 쓰고 읽어오기
# dataframe 의 일부 행을 하둡에 parquet 파일 형태로 쓴다.
df_sample <- df %>% filter(date_id == "2024-05-01")
spark_write_parquet(df_sample, "hdfs:///user/hive/warehouse/test.db/sparklyr_test/df_sample.parquet", mode = "append")
# parquet 파일을 읽어와 spark dataframe 객체에 저장한다.
df_sample_read <- spark_read_parquet(sc, path = "hdfs:///user/hive/warehouse/test.db/sparklyr_test/df_sample.parquet")
df_sample_read %>% head
해당 parquet 파일을 hive 테이블로 만들기
CREATE TABLE `tmp_sparklyr_test`(
`session_key` string,
`id` string)
STORED AS PARQUET
LOCATION
'hdfs://hadoop-carbon/user/hive/warehouse/test.db/sparklyr_test/df_sample.parquet''Tools > R' 카테고리의 다른 글
| R 로 벤다이어그램을 그려보자 VennDiagram 패키지 (0) | 2024.06.21 |
|---|---|
| R Standard evaluation 과 Tidy evaluation (0) | 2024.06.14 |
| R - 롱테일 분포의 히스토그램 그리기 (0) | 2024.05.08 |
| rstudio server 에서 github copilot 사용하기 (0) | 2024.04.26 |
| R 에서 폰트 사용하는 방법 (linux) (0) | 2024.04.04 |
