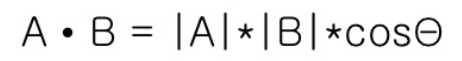기본 RAG 의 개념 : 기본 RAG (Retrieval Augmented Generation) 는 query 를 입력으로 받아 vector store 로부터 relevant 한 chunk 를 검색해서 가져온 후, 이를 prompt 에 추가해서 최종적인 답변을 출력한다.
사용된 개념
1. Relevance Check : vector store 에서 retrive 해온 chunk 가 relevant 한지 LLM 을 활용해서 검증한다.
2. Hallucination Check : retrieved chunk 를 참고해서 생성한 최종 답변이 hallucination 인지 여부를 LLM 을 활용해서 검증한다.
RAG 를 사용하기 위한 프레임워크로 langchain 을 사용한다. (비슷한 역할을 하는 Llamaindex 라는 프레임워크도 있다.)
목적: 3가지 웹문서를 vector store 로 저장하고, 이에 기반해 사용자 질문에 답변하는 RAG 를 만든다.
import getpass
import os
os.environ["OPENAI_API_KEY"] = "API_KEY 를 입력하세요."
from langchain_openai import ChatOpenAI
# openai의 gpt-4o-mini 모델 사용
llm = ChatOpenAI(model="gpt-4o-mini")
3. 문서를 로드한다.
- langchain 의 WebBaseLoader를 활용하며, beautiful soup 라이브러리를 활용해 html 태그 등을 parsing 해 본문 내용만 가져온다고 이해하면된다.
import bs4
from langchain import hub
from langchain_chroma import Chroma
from langchain_community.document_loaders import WebBaseLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
]
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=urls,
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
4. 로드한 문서를 Split 해서 Vector store 로 저장한다.
- chunk size 는 1000 토큰이며, 200의 오버랩을 허용한다. 각 청크간에 약간의 중복을 준다는 의미이다.
- chunk 를 vector 로 저장할 때, embedding 이 필요한데, openai 의 text-embedding-3-small 모델을 사용했다.
- retrieval 의 세팅으로 similarity 를 기준으로 6개의 chunk 를 가져오는 retrieval 객체를 정의한다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings(model="text-embedding-3-small"))
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever(search_type="similarity", search_kwargs={'k':6})
5. user query 를 입력으로 받아 관련도가 높은 chunk 를 retrieve 해온다.
- 가져온 chunk 6개를 1번 chunk : ... 2번 chunk : ... 이런 형식으로 텍스트 형식으로 저장한다.
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain import hub
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
prompt = hub.pull("rlm/rag-prompt")
user_query = "What is agent memory?"
retrieved_docs = retriever.invoke("what is agent memory?")
retrieved_docs_text = ""
for i in range(0,6) :
doc_content = retrieved_docs[i].page_content
retrieved_docs_text += f'{i+1}번 chunk: {doc_content}\n'
6. 목적에 맞는 최종 prompt 를 작성한다.
- relevance check 와 hallucination check 를 하여 기본 RAG 를 좀 더 개선하는 것이 목적이므로, 이에 대한 로직을 추가한 프롬프트를 작성한다. 전체적인 답변 생성 로직과 함께 필요한 정보 - 유저 query 와 retrieved chunk 를 제공해주어야한다.
query = {"question": {f"""
너는 유저로부터 query 를 입력 받아서 최종적인 답변을 해주는 시스템이야.
그런데, retrieval 된 결과를 본 후에, relevance 가 있는 retrieved chunk 만을 참고해서 최종적인 답변을 해줄거야.
아래 step 대로 수행한 후에 최종적인 답변을 출력해.
Step1) retrieved chunk 를 보고 관련이 있으면 각각의 청크 번호별로 relevance: yes 관련이 없으면 relevance: no 의 형식으로 json 방식으로 출력해.\n
Step2) 만약 모든 chunk 가 relevance 가 no 인 경우에, relevant chunk 를 찾을 수 없었습니다. 라는 메시지와 함께 프로그램을 종료해.
Step3) 만약 하나 이상의 chunk 가 relevance 가 yes 인 경우에, 그 chunk들만 참고해서 답변을 생성해.
Step4) 최종 답변에 hallucination 이 있었는지를 평가하고 만약, 있었다면 hallucination : yes 라고 출력해. 없다면 hallucination : no 라고 출력해.
Step5) 만약 hallucination : no 인 경우에, Step3로 돌아가서 답변을 다시 생성해. 이 과정은 딱 1번만 실행해 무한루프가 돌지 않도록.
Step6) 지금까지의 정보를 종합해서 최종적인 답변을 생성해
답변은 각 스텝별로 상세하게 출력해
아래는 user query 와 retrieved chunk 에 대한 정보야.
query : {user_query}\n
retrieved chunks: {retrieved_docs_text}"""}}
7. Prompt Template 을 기반으로 RAG Chain 을 호출해 최종 답변을 json 형식으로 출력한다.
- prompt template 은 프롬프트를 구조화된 형식으로 작성할 수 있게 도와주는 클래스이다.
- rag chain 은 query-> prompt -> llm -> output 파이프라인을 하나의 함수로 실행할 수 있도록 해준다.
json\n{\n "step1": {\n "1": "relevance: yes",\n "2": "relevance: yes",\n "3": "relevance: yes",\n "4": "relevance: yes",\n "5": "relevance: no",\n "6": "relevance: no"\n },\n "step2": "All retrieved chunks have relevance.",\n "step3": "The relevant chunks provide information about agent memory, which consists of both long-term and short-term memory. Agent memory is a long-term memory module that records agents\' experiences in natural language. Observations can trigger new statements, and the retrieval model assists in informing the agent’s behavior based on relevance, recency, and importance. Additionally, the reflection mechanism synthesizes these memories into higher-level inferences over time.",\n "step4": "hallucination: no",\n "step5": "Since hallucination is no, I will generate the answer again.",\n "step6": {\n "final_answer": "Agent memory refers to a long-term memory module that captures a comprehensive list of an agent\'s experiences in natural language, which can be used to inform the agent\'s behavior. It includes short-term aspects, such as in-context learning, as well as long-term memory that retains information over extended periods. The retrieval model helps prioritize memories based on relevance, recency, and importance, while the reflection mechanism synthesizes past events into higher-level insights that guide future behavior."\n }\n}\n
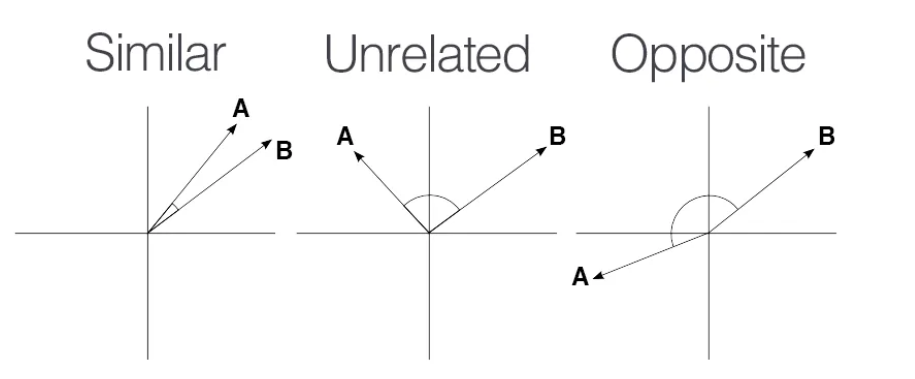
분석을 하다보면 두 집합이 얼마나 교차하는가? 를 이야기하고 싶을 때가 있다. A 그룹 유저는 B 그룹 유저와 N% 겹치고, B 그룹 유저는 A 그룹 유저와 M% 겹칩니다! 라고 말할 수 있다. 하지만 대량으로 이러한 교차성에 대한 값을 구해서 비교해 본다고 하자. 좀 더 심플하고 요약된 지표가 있다면 비교가 용이할 것이다. 교차성에 대한 정보를 0~1 사이의 값으로 나타내는 지표에는 어떤 것들이 있을까? 그리고 그 지표들 간에는 어떤 차이가 있을까?
우선, 벤다이어그램으로 표현한 데이터는 아래와 같이 binary vector 로도 표현할 수 있다. 예를 들어, 어떤 유저들이 A 서비스를 사용하는지 B 서비스를 사용하는지 여부를 binary vector 로 아래와 같이 나타낼 수 있다.
Sample
A서비스사용
B서비스사용
1
1
1
2
1
0
3
0
1
4
1
0
5
1
0
유사도란 A, B 두 벡터가 얼마나 유사한지를 보는 것으로 이해할 수 있다. 또는, 벤다이어그램에서 겹치는 부분이 얼마나 되는지를 의미하는 지표라고 해석할 수 있다.
1. Jaccard Index
Jaccard index 는 가장 기본적으로 생각할 수 있는 유사도 지표이다. 이것은 벤다이어그램에서 교집합 크기를 합집합 크기로 나눈 것으로 정의된다. 벤다이어그램에서 교차되는 부분의 면적을 전체 원의 면적으로 나눈 것이다.
$$ J(A,B) = \frac{{|A \cap B|}}{{|A \cup B|}} $$
$$ J(A,B) = 100 / 1300 = 0.08 $$
Jaccard index 전통적으로 두 문서의 유사도를 비교할 때 쓰이기도 한다. A 문서와 B 문서의 유사도를 비교할 때, 두 문서에 등장하는 단어들을 하나의 샘플로해서 A,B 문서에 속했는지 여부를 이진 벡터로 만들 수 있을 것이다. 최종적으로 A문서와 B문서의 이진벡터를 만들 수 있고, 이를 통해 Jaccard index 를 구할 수 있다.
2. Dice coefficient
Dice coefficient는 두 집합의 교집합 크기의 두 배를 두 집합 크기의 합으로 나눈 값이다.
$$ D(A,B) = \frac{{2|A \cap B|}}{{|A| + |B|}} $$
$$ D(A,B) = \frac{100*2}{1000+400} = 0.14$$
3. Kulczynski similarity index
A 의 크기가 1만, B의 크기가 10, 그리고 A교집합B가 9라고 하자. B의 입장에서는 90%가 A와의 교집합인데 Jaccard index 나 Dice coefficient 는 낮게 계산된다. Kulczynski similarity 는 A 와 B 각각에서 교집합의 비율을 평균낸 값이기 때문에, B 입장에서 90%인 교집합의 비율이 동등하게 지표에 반영된다. Kulczynski similarity 는 두 집합의 크기 차이가 클 때, 이를 보정하는 지표로 볼 수 있다.
즉, Kulczynski similarity 두 데이터 셋 간의 크기 차이가 결과에 미치는 영향을 감소시킨다. 반면, Jaccard index 나 Dice coefficient 의 경우, A,B의 크기의 차이가 결과에 영향을 미친다.
4. Cosine similarity (코사인 유사도)
Cosine similarity 는 두 벡터의 코사인 값을 통해 유사도를 구하는 개념이다. 코사인 유사도는 이진 벡터가 아닌 데이터에서도 광범위 하게 사용되는 measure 이다. 예를 들어, 자연어 처리에서 두 워드 임베딩 값의 유사도를 볼 때 쓰이기도 한다. 벤다이어그램에서는 두 벡터가 이진 벡터이기 때문에 두 벡터의 내적은 (1,1) 인 행의 숫자, 즉 교집합의 크기를 의미한다. 또한, 각 벡터의 크기는 집합의 크기의 제곱근이다.
이진 분류 모델의 최종 예측 값은 일반적으로 0~1사이로 나오게된다. 특정 임계치를 기준으로 테스트 양성과 테스트 음성을 분류한다. 예를 들어, 임계치를 0.5로 잡는다면, 0.5 이상인 경우를 테스트 양성, 0.5 미만인 경우를 테스트 음성으로 정의한다. 이 방법을 통해 아래와 같은 2x2 테이블을 만들 수 있다.
양성 (Disease)
실제 음성 (No Disease)
테스트 양성 (Positive)
50
10
테스트 음성 (Negative)
5
100
True Positive (TP): 50
False Positive (FP): 10
False Negative (FN): 5
True Negative (TN): 100
Sensitivity = Recall (민감도)
sensitivity 는 실제 질병인 사람 중에 테스트 양성인 사람의 비율이다.
-> 50/55 = 0.909
Specificity = Negative Recall (특이도)
specificity 는 실제 질병이 아닌 사람 중에 테스트 음성인 사람의 비율이다.
-> 100/110 = 0.909
Positive Predictive Value = Precision (양성 예측도, PPV)
ppv 는 양성으로 예측한 사람 중에 실제 질병인 사람의 비율이다.
-> 50/60 = 0.833
Negative Predictive Value (음성 예측도, NPV)
npv 는 음성으로 예측한 사람 중에 실제 질병이 아닌 사람의 비율이다.
-> 100/105 = 0.952
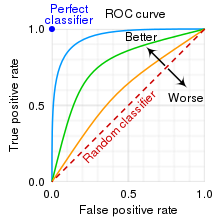
ROC 커브와 AUC (Area under curve)
임계치를 변화시키면서 1-specificity, sensitivity 그래프를 그린 것이 ROC 커브이다. 위 두 지표를 통해 그래프를 그리는 이유는 sensitivity 와 specificity 간에 트레이드오프관계가 있기 때문에, 이 관계를 시각적으로 표현하여 모델의 성능을 평가하기 위해서이다.
1-specificity = False Positive Rate (FPR)
sensitivity = True Positive Rate (TPR)
임계치가 낮아지면 모델은 더 많은 사례를 양성으로 분류하게 되어 True Positive Rate와 False Positive Rate가 모두 증가한다. 반대로, 임계치가 높아지면 모델은 더 적은 사례를 양성으로 분류하게 되어 True Positive Rate와 False Positive Rate가 모두 감소한다.
만약 모델 2에서 beta2가 0인 경우, 모델1 이 된다. 따라서 두 모델은 nested 관계에 있다.
이 경우 변수가 많은 모델2가 무조건 likelihood 가 높게 된다.
이 때, Likelihood ratio 가 카이제곱분포를 따르게된다. 자유도는 두 모델의 모수 개수의 차이가 된다. 여기서 L0가 간소한 reduced 모델이고, L1이 full model 이다. 이는 full model 과 reduce model 의 log likelihood 의 차이의 2배이다.
만약 위 통계량이 유의미한 카이제곱 값을 가지면, full model 이 reduced model 보다 좋은 것이다. 따라서 full model 을 채택한다. 만약 카이제곱값의 p-value 가 0.05보다 크다면, full model 이 reduced model 보다 좋지 않은 것이므로, reduced 모델을 채택한다.
이러한 경우 AIC 를 통해 두 모델 중 어떤 모델이 좋은지를 판단할 수 있다. p는 변수의 숫자로 패널티텀이다. unnested 관계일 때, likelihood ratio test 를 적용할 수 없는 이유는 unnested 관계일 때는 likelihood ratio 가 카이제곱분포를 따르지 않기 때문이다.
$$ AIC = -2(Log L_1 - p) $$
만약 모델1 의 로그 우도가 -120 이고, 모델3의 로그 우도가 -115 라고하자. 모델3의 로그 우도가 더 높다.
모델1의 AIC = -2(-120 - 2) = 244
모델3의 AIC = -2(-115 - 3) = 236
만약 모델3의 추정 파라미터 수가 2개였다면, AIC 는 234였을 것이다. 파라미터로 인한 패널티 2점이 들어갔음을 알 수 있다. 이 경우 패널티를 고려해도 모델3의 AIC가 낮기 때문에 모델3을 채택한다.
x1, x2 ... 가 주어졌을 때, Y를 예측하고 싶다. 근데 특정 조건하에서 Y 는 정해진 값이 아니라 어떤 분포를 따른다고 가정하고, 그 평균을 예측하고 싶을 때, 일반화 선형 모형을 활용한다. 기본적인 회귀분석에서는 반응변수가 정규분포를 따른다고 가정하고 모델링하는데, 일반화 선형 모형은 Y가 다른 분포를 따르는 경우에도 활용할 수 있는 모델링 방법이라고 볼 수 있다.
일반화 선형모형에서는 반응변수가 어떤 분포를 따른다고 가정하기 때문에 랜덤성분 (random component) 이라고 부르고, 반응변수의 평균을 설명하기 위한 설명 변수들의 함수 (위 식에서 우측부분) 를 체계적 성분 (systematic component) 이라고 부른다. 랜덤성분과 체계정 성분을 연결하는 함수를 연결함수(link function) 라고 부른다.
Y가 정규분포를 따른다면, 평균값이 -무한대~+무한대일 수 있고, Y 가 베르누이 분포를 따르면 Y의 평균이 0~1사이의 값이다. 따라서 적당한 연결함수를 통해 값의 범위를 변환하는 것이 필요하다.
또한, 일반화 선형 모형에서는 Y 가 지수족 분포를 따른다고 가정한다. 지수족 분포에는 정규분포, 이항분포, 포아송분포, 감마분포 등이 있다. Y가 따른다고 가정한 분포에 따라 알맞는 연결함수를 적용해준다. GLM 에서 지수족 분포가 중요한 개념이지만, 다소 심플하게 내용을 설명하기 위해 지수족 관련 내용은 설명하지 않겠다.
만약, Y가 정규분포를 따르는 경우에 가장 기본적으로 항등함수를 이용할 수 있다. 연결함수가 항등함수인 경우, 일반 선형 모형이라고 한다. (general liner model) (generalied linear model 과 다르다.).
$$ \mu = \alpha + \beta x $$
연결함수가 항등함수인 경우 beta 값의 해석은 매우 쉽다. "X가 1단위 증가했을 때 반응 변수가 beta 만큼 증가한다" 고 해석한다.
Y가 베르누이분포를 따르는 경우 0~1의 값을 무한대로 변환하는 연결함수로 여러가지를 이용할 수 있다. 가장 대표적인 것이 로짓함수이다. 로짓함수를 사용한 변수가 1개인 일반화 선형모형은 아래와 같이 정의된다. 이를 로지스틱 회귀분석 (logistic regression) 이라고 부른다.
$$ log(\frac{\mu}{1-\mu}) = \alpha + \beta x $$
좌측을 살펴보면 log odds 라는 것을 알 수 있다. (=> log(성공확률/실패확률) 이므로) 즉, 로지스틱 회귀분석은 log odds 를 설명변수들의 조합으로 예측하는 것을 의미한다. odds 가 아닌 확률(평균) 의 관점에서 로지스틱 회귀분석은 아래와 같이 써볼 수 있다.
또한 로지스틱 회귀 분석에서 중요한 것은 beta 값의 해석이다. 만약 x가 연속형인 경우 x+1과 x의 odds 를 구해서 odds ratio 를 구해보자. 위 식에 넣어 계산해보면, OR = exp(beta) 가 나온다. 양변에 log 를 취해주면 log(OR) = beta 라는 것을 알 수 있다.즉, x가 1단위 증가했을 때의 log(OR) 값이 beta 라는 것을 알 수 있다.
한편, Y가 베르누이 분포를 따르는 경우에 사용할 수 있는 다른 연결함수로는 프로빗 연결함수가 있다. 프로빗 연결함수를 사용한 일반화 선형 모형을 프로빗 모형이라고 부른다. 프로빗 모형은 표준정규분포의 누적분포함수의 역함수를 연결함수로 사용한다. 누적분포함수의 역함수를 연결함수로 사용한다는 의미가 무엇일까? 누적분포함수는 0~1사이의 값을 갖는다. 즉, 어떤 -무한대~무한대에 있는 X라고하는 값을 0~1 사이로 변환하는 함수이다. 이에 역함수이기 때문에 0~1사이의 값을 -무한대~무한대로 바꾸어주는 함수가 된다.
도수 자료의 경우에는 일반화 선형모형중 포아송 회귀분석을 해볼 수 있다. 도수 자료란 반응 변수가 도수 (count)로 이루어진 자료를 의미한다 (예를 들어, 교통사고 수, 고장 수 등...). 도수자료는 양의 방향에서만 존재한다. 교통사고수가 마이너스일 수는 없다. 반면, 설명변수의 조합인 체계적 성분은 -무한대~무한대의 범위를 갖는다. 이를 변환하기 위해서, 포아송 회귀분석에서는 연결함수로 log 를 활용하여 좌변이 -무한대~무한대의 값을 갖도록 변환한다. 포아송 회귀분석 식은 아래와 같다.
$$ log(\mu) = \alpha + \beta x $$
이는 평균의 관점에서는 아래와 같이 쓸 수 있다.
$$ \mu = exp(\alpha + \beta x) $$
x가 t일 때와 t+1일때의 mu 값을 비교해보자. 위 수식에 대입하면x가 t+1 일 때의 mu 와 t 일 때의 mu 의 ratio 는 exp(beta) 가 됨을 알 수 있다. 즉, 포아송 회귀분석과 같은 log linear regression 에서 beta 를 해석하는 방법은 "x 가 1단위 증가했을 때 Y값의 평균이 exp(beta)배 증가한다." 이다.
포아송 회귀 관련해서는 종종 이런 문제가 발생할 수 있다. 만약, X가 차량 사고수에 미치는 영향을 포아송 회귀로 모델링을 하려고하는데, 지역별로 데이터가 수집 되었고, 지역별로 기본적인 차량의 개수가 달라 사고수가 이에 영향을 받는다고 해보자. 이 때, "사고율" 을 반응 변수로해서 모델링할 수 있다. 차량의 개수를 t라고 하자.
$$ \log(\mu / t) = \alpha+\beta x $$
사고수의 관점에서 아래와 같은 수식으로 변환할 수 있다. 이 때, log(t) 를 offset 이라고 한다.
선택편향은 특정 그룹을 선택해서 분석했을 때, 다른 그룹 또는 전체를 대상으로 분석했을 때와 다른 결론이 나오는 것을 의미한다. 아래와 같이 왼쪽 그림에서는 X,Y 의 연관성이 없지만, X+Y가 1.2 이상인 그룹만 선택해서 봤을 때는 X,Y의 음의 상관성이 생기는 것을 알 수 있다. 이러한 선택 편향은 우리의 실생활에서도 많이 발생한다.
Collider bias
Collider bias는 X와 Y가 모두 영향을 미치는 Z라고 하는 변수가 있을 때, Z를 고정시켜 놓고 보면, X (exposure) 과 Y (outcome) 에 연관성에 편향이 생기는 현상을 의미한다.
왜 Collider bias 가 발생할까? 이에 대해 사고적으로 이해하는 방법에는 "explaining away" 라고 하는 개념이 있다. 예를 들어, X 를 통계학 실력이라고 하고, Y를 아첨 능력이라고 하자. 그리고 X,Y 가 모두 승진 (Z) 에 영향을 준다고 해보자. 이 때, 승진 대상자만을 놓고 통계학 실력과 아첨 능력의 관계를 보면 둘 사이에는 음의 상관성을 확인할 수 있다. (이는 정확히 위 selection bias 에서 설명하는 그림과 같다.)
이처럼 실제로는 통계 실력과 아첨 능력에는 아무런 상관성이 없으며, 승진에 영향을 주는 원인 변수일 뿐인데, 승진 대상자를 놓고 봤을 때는 둘 사이에 연관성이 생긴다 (false association). 승진한 어떤 사람이 아첨능력이 매우 좋다고 했을 때, 이것이 승진의 이유를 explain 해주므로, 이 사람의 통계학 실력은 좋지 않을 것이라고 '추정' 할 수 있을 것이다. 또한, 어떤 사람이 통계 실력이 매우 좋지 않음에도 불구하고 승진했을 때, 이 사람은 아첨 능력이 뛰어날 것이라고 추정할 수 있다. 이처럼 둘 사이에 음의 상관성이 존재하는 것을 직관적으로 이해할 수 있다.
범주형 자료 분석에서 코크란-멘텔-헨젤(Cochran-Mantel-Haenszel) 검정의 목표는 Z 가 주어질 때, X와 Y가 조건부 독립인지를 검정하는 것이다.즉, Z를 고려했을 때, X-Y의 연관성이 존재하는지를 판단하는 검정이라고 할 수 있다. 이는 인과추론에서 말하는 X,Y가 조건부 독립 (conditional independence) 인지를 확인하는 검정이라고 할 수 있다. 보통 Z는 confounder 로 설정하는 경우가 많다. 만약, conditional independence 가 아니라고 한다면, Z 를 고려함에도 X-Y 연관성이 존재하는 것이고, 이는 X,Y 의 인과성에 대해 조금 더 근거를 더해준다고 할 수 있다. CMH 검정은 2 X 2 X K 표에 대해서 활용할 수 있다. (K 는 Z의 수준 개수)
그룹 i 에서의 흡연과 폐암의 연관성
폐암X
폐암O
흡연X
a
b
흡연O
c
d
주요 지표
n = a+b+c+d
p1 = (a+b)/n (흡연X 비율)
p2 = (a+c)/n (폐암X 비율)
m = n*p1*p2
CMH 통계량의 계산
그룹 i 에서의 CMH 통계량은 아래와 같다.
$$ \frac{(a-m)^2}{m(1-p_1)(1-p_2)} $$
최종적인 CMH 통계량은 모든 그룹 i에서 위 값을 다 구해서 더한 것이다. 이 값은 자유도가 1인 카이제곱분포를 따른다는 것을 이용해 검정한다. 만약, 충분히 이 값이 큰 경우 그룹을 고려했을 때, 흡연과 폐암에 연관성이 있다고 결론을 낼 수 있다.
위 수식에서 a-m 은 관측값에서 기대값 (평균) 을 빼준 것이고, 분모는 a의 분산을 의미한다. 이 분산은 초기하분포의 분산이다. 즉, cmh 통계량에서는 a가 초기하분포를 따른다고 가정한다. 즉, 수식은 a 에서 평균을 빼주고 표준편차로 나눈 값에 제곱이라고 할 수 있다.
MH 공통 오즈비
그룹1
X
O
X
10
20
O
30
40
=> OR = 10*40 / 20*30 = 2/3
그룹2
X
O
X
4
1
O
1
4
=> OR = 4*4 = 16
1) 두 그룹의 공통 오즈비를 구하는 방법에는 단순히 두 그룹의 오즈비의 평균을 구하는 방법이 있을 수 있다. 이 경우 그룹2의 샘플수가 적음에도 불구하고 평균 오즈비는 8에 가깝게 높게 나온다.
2) a*d 의 값을 모두 더한 값을 b*c 를 모두 더한 값으로 나누어주는 방법이 있다. 이러면 (10*40 + 4*4) / (20*30+1) = 0.69 가 나오게 된다. 이 값은 샘플수가 많은 그룹의 값으로 지나치게 치우친다.
3) MH 공통 오즈비는 중도적인 방법으로 두 방법의 단점을 보완한다. 2) 방법에서 샘플수의 역수로 가중치를 줌으로써, 샘플수가 많은 그룹이 계산에 미치는 영향력을 의도적으로 줄여준다.
(10*40/100 + 4*4/10) / (20*30/100 + 1/10) = 0.91
즉, MH 공통 오즈비를 사용하면, 지나치게 그룹1에 치우치지 않으면서 적당한 공통 오즈비가 추정된다. 또한, 로그 MH 공통 오즈비의 분산을 계산할 수 있기 때문에, 공통 오즈비의 신뢰구간 및 오즈비가 유의미한지를 추론할 수 있다는 장점이 있따.
예를 들어, 공통 오즈비가 0.91인 경우 로그 공통 오즈비는 -0.094이다. 그리고, 로그 공통 오즈비의 표준편차를 예를 들어 0.02라고 하자. 그러면 공통 오즈비의 95% 신뢰구간은 아래와 같이 계산된다.
비율의 비와 오즈비는 어떤 treatment의 효과(effect) 를 설명할 때 좋다. 비율의 비는 특히, 설명할 때 좋다.
- 예를 들면, 어떤 위험인자가 질병에 미치는 영향이 있는지를 설명할 때는 비율의 비를 활용하는 것이 좋다.
- 흡연의 reltavie risk 가 3이라는 말은 흡연을 하면 폐암 발생 위험을 3배 높인다고 해석할 수 있다.
비율의 차는 전체 모수에서의 impact 를 설명할 때 좋다.
- 어떤 요인 A의 risk difference 는 10% 인데 relative risk 는 2라고 하자.
- 어떤 요인 B 의 risk difference 는 1%인데 relative risk 는 10이라고 하자.
- 이 때, 요인 B 의 effect size는 더 크지만, 실제 요인의 중요도는 A가 더 클 수 있다.
오즈비는 y=1의 비율이 적을 때, 상대위험도와 값이 유사하다.
- 만약의 y가 폐암과 같이 질병인 경우, P(Y=1) 은 유병률이다.
- 즉, 유병률이 작은 질병의 경우 오즈비를 relative risk 처럼 해석할 수 있다.
오즈비는 샘플이 불균형하게 추출한 경우에도 사용할 수 있는 지표이다.
- 비율의 차 또는 비율의 비는 샘플링 바이어스의 영향을 받는다.
- 만약, 흡연자 100명, 비흡연자100명을 선정해서 폐암여부를 비교할 때 비율의 비(relative risk) 에는 bias 가 생긴다. 이는 모집단에서 계산한 값과 차이가 생긴다는 의미이다.
- 그러나, 오즈비의 경우 모집단에서의 값과 오즈비와 비교하여 bias 가 없게 된다.
- 왜 오즈비는 샘플링 영향이 없는지 관련해서는 이 포스팅을 참고할 수 있다.
ratio 에 로그를 취한 값은 유용하다.
- 비율의 비 또는 오즈비는 매우 skew 된 값이다.
- ratio는 0에서 무한대의 값을 갖는다.
- ratio 에 log 를 취해주면 -무한대~ +무한대의 값을 갖게 된다.
- 만약, 어떤 A약의 효과가 B약의 효과보다 1.5배 있다 라는 것을 반대로 말하면 B 약의 효과가 비 약의 효과보다 1/1.5배 = 0.67배 있다라는 것이다. 그러나, 1.5배와 0.67배가 한눈에 역수 관계에 있다는 것을 알기 어렵다. 1.5배는 1로부터 0.5 떨어져 있고, 0.67은 1로부터 0.33 떨어져있다. 만약, 1.5와 0.67에 log를 취해주면, 각각 0.405, -0.405로 나오게 되어, 역관계에 있다는 것을 바로 확인할 수 있다.
X-> Y 의 인과적 관계 파악을 위해, 간단한게 심플 회귀 분석을 진행할 수 있다. 만약 X 와 correlation 이 있고, Y 의 determinants 인 Z 라고 하는 변수가 보정되지 않는다면, omitted variable bias 가 발생한다. 이러한 상황에서 omitted variable bias 의 방향은 다음과 같이 알 수 있다.
1) Z->X 에 영향을 주는 방향
2) Z->Y 에 영향을 주는 방향
1) 2) 를 곱하면 이것이 bias 의 방향이 된다.
예를 들어, 소득(X)이 의료비 지출(Y)에 주는 영향을 파악하려고 한다. 이 때, 건강 상태(이를 개인이 갖고 있는 질병의 갯수라고 하자) 를 보정하지 않으면, omitted variable bias 가 발생하게 된다.
질병의 개수는 소득에 negative effect 이다. 질병의 개수가 증가할 수록 소득은 감소한다.
질병의 개수는 의료비 지출에 positive effect 이다. 질병의 개수가 증가할 수록 의료비 지출은 증가한다.
1) 2) 를 곱하면 negative 가 되기 때문에 bias 의 방향은 negative 가 된다. 따라서 건강 상태를 변수로 포함하지 않고 소득과 의료비 지출의 관계를 파악하여 나온 회귀 계수는 underestimate 이 되었다고 볼 수 있다. 만약, 동일한 건강상태에 있는 사람들만을 대상으로 소득과 의료비 지출의 연관성은 더욱 강하게 측정될 것이다.
충분 통계량 (sufficient statistics) 란 계수를 설명할 수 있는 충분한 정보를 가지고 있는 통계량입니다. 예를 들어, 평균이 theta 이고 분산이 1인 정규분포에서 X1,X2,X3...Xn을 관찰하였고, X의 표본 평균값을 구해서 3이 나왔습니다. 그러면 X의 평균값 이외에 X1,X2,X3,...Xn 각각에 대한 데이터를 추가적으로 봄으로써 theta의 추정에 도움이 되는 다른 정보를 얻을 수 있을까요? 만약 추가적인 정보가 없다면, X의 표본 평균은 theta 를 설명할 수 있는 충분한 통계량이라고 볼 수 있습니다. 좀더 포멀하게는 아래와 같이 충분 통계량을 정의할 수 있습니다.
$$ f(X|Y;\theta) \ne g(\theta) $$
위 식을 만족하면 Y는 theta 에 대한 충분통계량입니다. 위 식의 의미는 Y가 주어졌을 때, X의 pdf 가 theta 에 의존적이지 않다라는 의미입니다. 즉, Y가 theta 에 대한 모든 정보를 갖고 있다는 의미입니다.
충분 통계량의 예시
예를 들어, 베르누이를 2회 시행해서 X1,X2 를 구했다고 합니다. X는 0 또는 1의 값을 갖습니다.
이 때, X1 + X2 는 베르누이의 모수 p 에 대한 충분 통계량일까요?
만약 X1+X2가 0이라면, X1,X2가 가질 수 있는 경우의 수는 (0,0) 입니다.
만약 X1+X2가 1이라면, (0,1), (1,0) 입니다.
만약 X1+X2가 2라면 (1,1) 입니다.
즉, X1+X2 가 주어졌을 때, (X1,X2) 의 분포 (pmf) 는 theta 와 독립적입니다. 따라서 X1+X2 는 충분 통계량이라고 볼 수 있습니다. 이 의미는 만약에 X1+X2 가 1이라고 한다면, X1이 1이냐, X2가 1이냐는 적어도 계수를 추정함에 있어서 중요하지 않다는 것입니다. 위 예시에서는 베르누이 2회 시행에서 예시를 들었으나, N번의 베르누이 시행에서도 X1+...+Xn은 충분 통계량입니다. 만약 100번의 베르누이 시행에서 53번 성공했다라고 한다면, 몇 번째 시행에서 성공했는지는 계수 추정에 있어서 추가적인 정보를 주지는 않습니다.