MLE는 관측한 데이터를 가장 잘 설명할 수 있는 계수(parameter) 를 찾는 것이 목적이라고 할 수 있습니다. 데이터 분석을 하다보면 데이터를 관측하고, 이를 통해 모델의 계수를 추정해야할 때가 있습니다. 우선likelihood 를 정의해보면, 특정 계수에서 데이터를 관찰할 가능성을 의미합니다.
예를 들어, 계수가 0.4인 베르누이분포를 100번 시행해서 45번의 성공이 발생했다고 합시다. likelihood 란 계수의 함수이며, 이 경우에서는 아래와 같이 나타낼 수 있습니다.
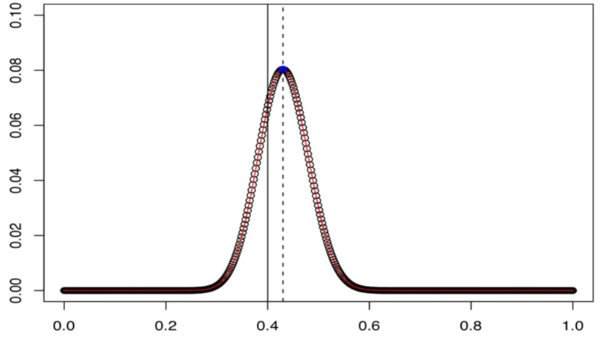
이 그래프는 계수가 0.1일 때 데이터를 관찰할 확률, 0.2 일때 관찰할 확률 등등.. 그 값을 모두 구해 계수와 likelihood 의 관계를 나타내는 그래프라고 볼 수 있습니다. 이 때, likelihood 는 계수가 0.45 일 때 최댓값을 갖습니다. 따라서 MLE 는 0.45 입니다. 이 경우 MLE 와 실제 계수에 차이가 있습니다. 하지만, 관측하는 데이터의 갯수가 증가할 수록, MLE 는 실제 계수인 0.4로 수렴해갈 것입니다 (하지만 모든 분포에서 실제 계수에 수렴하게 되는 것은 아닙니다).
x축: 계수 추정값 / y축: likelihood
Probability와 Likelihood 는 다른 개념입니다.Likelihood 는 데이터가 주어져있고, 이를 통해 계수를 추정하기 위한 것이라고 볼 수 있습니다. Probability 란, 어떤 모델의 계수가 주어졌을 때, 특정 outcome 을 예측하기 위한 것입니다.
Maximum likelihood 를 만드는 지점을 찾기
그러면 likelihood function 의 값을 최대화하는 계수값을 어떻게 구할 수 있을까요? 일반적으로는 likelihood function 을 미분해서 값이 0인 지점을 찾으면 됩니다. 또는 계산상의 이점을 위해 log likelihood 를 미분해서 값이 0이 되는 지점을 찾습니다. likelihood 를 미분해서 0이 되는 지점이나, log likelihood 를 미분해서 0이 되는 지점이나 값은 같기 때문입니다.
예를 들어, 앞서 살펴본 베르누이 분포에서 MLE 를 통해 계수 추정을 해봅시다. 베르누이 분포의 pmf 는 아래와 같이 정의 됩니다.
위 score를 0으로 만드는 theta (계수) 값은 표본 평균입니다. (이와 같이 많은 경우, MLE 는 표본 평균인 경우가 많습니다.)
$$ \hat{\theta} = \bar{X} $$
또한 이 경우 표본 평균의 기댓값이 모평균이기 때문에 unbiased estimation 이라고 볼 수 있습니다.
MLE 는 항상 unbiased 는 아니다.
하지만 MLE 의 경우 모든 경우에 unbiased 인 것은 아닙니다. 예를 들어, uniform distribution(0,theta) 의 계수를 MLE 로 추정값은 관측한 데이터중 최댓값이 됩니다(관련된 자세한 설명은 생략하겠습니다). 그리고 이값의 기댓값은 아래와 같이 n에 의존하는 값이 되기 때문에 biased estimation 이라고 할 수 있습니다.(참고링크)
MLE 의 분산과 Efficiency
그럼에도 불구하고 MLE 는 관측 데이터가 많으면 많을 수록 가능한 unbiased estimator 집합들이 가질 수 있는 분산의 최솟값으로 수렴한다는 큰 장점을 가지고 있습니다. 즉, MLE 는 이론적으로 나올 수 있는 가장 작은 분산을 가진다는 의미이며, 이를 "Asymptotically efficient 하다" 라고 부르기도 합니다.
이 때, 이론적으로 나올 수 있는 분산의 최솟값을 Rao-Cramer Lower Bound 라고 부릅니다. 어떤 unbiased estimator Y가 있을 때, Y의 분산의 최솟값은 아래과 같습니다.
$$ var(Y) \ge \frac{1}{nI_1{\theta}} $$
여기서 I는 fisher information 이고 아래와 같습니다. I_1 은 데이터 하나로 구한 fisher information 입니다.
$$ I(\theta) = E(-l''(\theta)) $$
$$ I(\theta) = nI_1(\theta)$$
베르누이 분포에서 fisher information 과 rao-cramer lower bound 를 구해봅시다. 데이터 1개에서 log likelihood 를 구하면 fisher information 을 구하고 이를 통해 rao-cramer lower bound 를 구할 수 있습니다.
이 값은 rao-cramer lower bound 의 값과 같습니다. 따라서 베르누이 분포에서 MLE 는 최소 분산을 가지며, efficient estimator 라고 할 수 있습니다. 또한 unbiased 이기 때문에, minimum variance unbiased estimator (MVUE) 라고 부르기도 합니다.
LD score regression 은 Genome-wide association study(GWAS) 에서 특정 trait 의 polegenicity 를 추정하기 위해 사용하는 방법이다. LD score regression 은 GWAS summary statatistics 를 기반으로 SNP-heritability 추정, SNP-heritability 기반 genetic correlation 의 추정 등 다양한 measure 들을 계산하는데에 활용되고 있다. 본 문서에서는 LD score regression 의 등장 배경과 의미에 대해 알아보고자 한다.
polygenic trait 에 대해 GWAS 를 수행한 후에, 각 SNP 들의 p-value 의 분포를 살펴보면 null distribution 과 비교하여 값들이 낮게 나타나는 것을 확인할 수 있다. 이렇게 높게 나타나는 검정 통계량은 형질이 polygenic 함을 의미할 수도 있지만, confounding bias 나 population stratification 가 영향을 주었을 수도 있다. polygenicity 로부터 위와 같은 bias 를 분리해내는 방법이 LD score regression 이며, LD score regression 은 이 과정에서 Linkage Disequillibrium (LD) 와 검정 통계량 (test statistics) 의 관계를 이용한다.
"Both polygenicity (i.e. many small genetic effects) and confounding biases, such as cryptic relatedness and population stratification, can yield inflated distributions of test statistics in genome-wide association studies (GWAS). "
LD score regression 의 아이디어
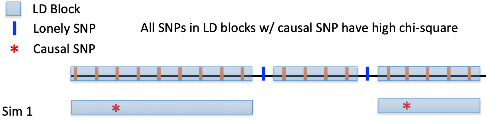
어떤 SNP j 에 대해서 이 LD 관계에 있는 SNP 들이 많을 수록, polygenic 한 trait 에 대해서는 test statistics 이 높게 나올 가능성이 높다. LD 는 유전자 변이간의 연관성을 의미한다. 만약, 어떤 SNP 이 LD 관계에 있는 SNP 이 많다고 하면, causal variant 와 LD 관계일 가능성이 높고, causal variant 와 LD 관계라면, test statistics 가 높게 나온다. 따라서 LD 관계에 있는 SNP 이 많으면, test statistics 가 높게 나올 가능성이 높다. LD score regression 은 이렇게 LD 관계에 있는 SNP 이 많은 SNP 일 수록 test stat 이 높게 나올 가능성이 높다라는 관계를 이용하는 방법이다. 그리고, 이러한 경향성이 강한 trait 일 수록 polygenicity 가 강하다고 말할 수 있다. (즉, LD score 와 test stat 의 연관성이 강할 수록 polygenic effect 로 phenotype 을 설명할 수 있는 비중이 높다.)
GWAS test statistics
LD score regression 에서는 chi-square value 를 regression 의 종속변수로 선정한다. chi-square value 는 무엇일까? 일반적으로 GWAS 결과로 effect size (beta) 와 standard deviation (sd) 값이 나오게 된다. 이 때, beta/sd 를 z-value 라고 한다. (이는 beta = 0 이라는 귀무가설 하에 구한 z-score 이다.) z-value 관측된 beta 값이 0으로부터 몇 standard deviation 떨어져 있는지를 의미한다. 이 때 chi-square value 는 z value 의 제곱으로 계산된다. z-value 는 표준정규분포를 따르며, 표준 정규 분포의 확률변수 z 의 제곱은 자유도가 1인 chi-square 분포를 따르기 때문이다.
LD 와 LD score 는 무엇일까?
먼저 LD 와 LD score 를 계산하는 방법을 간단히 알아보자. 일반적으로 두개의 SNP A,B 의 LD 와 관련된 지표 D 와 r^2 은 아래와 같이 계산된다. D 값이 높을 수록 A,B 변이는 함께 나타날 가능성이 높음을 의미 한다. 만약, P(A)=0.3, P(B)=0.4, P(A,B) = 0.15 라고 하면, D는 0.03 으로 계산되며, A,B 는 LD 관계가 아닐 것으로 판단된다.
특정 SNP j 에 대한 LD score 는 아래와 같이 계산된다. LD score 는 각각의 SNP 에 대해 다른 모든 SNP 들과의 LD 값 (r^2) 들을 더한 값으로 볼 수 있다.
$$ l_j = 1 + \sum_{k \neq j}r_{jk}^2 $$
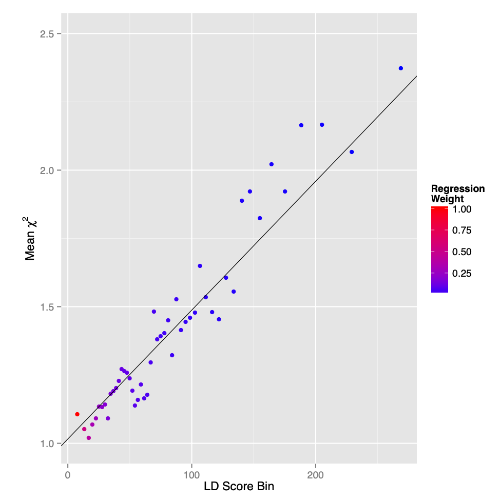
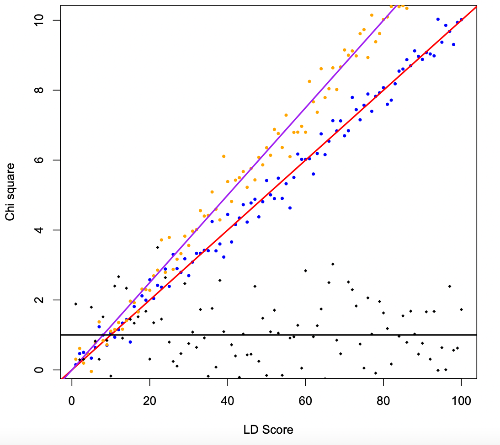
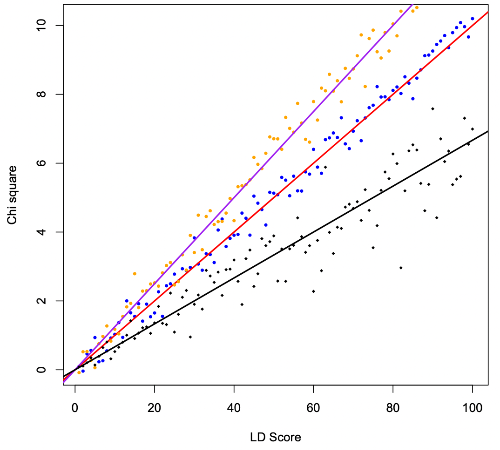
LD score 와 test statistics (chi square value) 의 관계를 아래와 같이 시각화해볼 수 있다. 아래 차트는 LD score 의 bin 과 평균 chi-square value 의 관계를 보여준다. 직선은 아래 점들을 대상으로 단순 선형 회귀 분석을 한 결과를 표현한다 (아래 차트에서 각 점들에 해당 하는 SNP 의 갯수에 가중치를 두어 regression 을 돌리면 결국 전체 snp 과 chi-square 를 대상으로 regression 을 돌린 것과 같은 값이 나오게 될 것이다).
LD score 와 test stat (chi-square value) 의 관계 및 선형 회귀 분석의 결과
이를 LD score regression 이라고 하며, 이 선형 회귀 분석에서 기울기는 polygenicity 를 반영하고, 절편은 bias 를 반영한다. LD 와 chi-square 의 연관성 (기울기) 이 polygenicity 이며, 전반적으로 chi-square 가 inflation 이 된 정도 (절편) 가 bias 라는 것이다. 이러한 방법을 통해 polygenicity 와 bias 를 분해할 수 있게 된다.
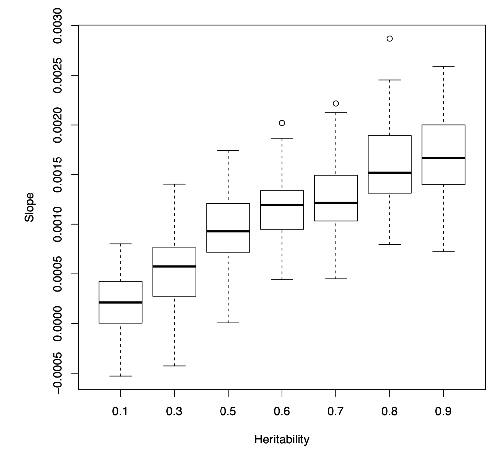
또한, LD score regression 에서 기울기는 heritability 를 반영한다. 아래 그림과 같이 heritability 가 높을 수록 LD score regression 의 기울기가 커지게 된다.
다양한 heritability 값들에 대한 LD score regression slope 와의 관계 (simluated data)
또한, 기울기는 샘플 사이즈와 사용한 SNP의 전체 개수에도 영향을 받는다. 샘플 사이즈 N 이 커질 수록 chi-square 값이 커지고, 사용한 SNP 의 개수가 많아질 수록, LD score 의 값이 기본적으로 높아진다. 이를 고려하여, 특정 SNP j 의 test stat 을 설명하는 아래와 같은 regression 모델을 고려할 수 있다.
$$ E[\chi^2 | l_j] = Nh^2/M l_j + Na + 1 $$
기울기는 heritability 와 N, M 으로 분해하여 나타낸다. 또한 절편은 Na + 1 로 표현되는데, 이 때, a 가 population structure 또는 confounding bias 와 같은 요인으로 인해 test stat 이 inflation 된 정도를 의미한다. 1이 더해진 이유는, LD score 가 0 인 SNP (즉, 그 어떤 SNP 과도 LD 관계에 있지 않은 SNP) 의 경우, chi-square value 는 causal variant 가 아닌 이상 기댓값은 1일 것이다 (자유도가 1인 chi-square distribution 의 평균값). 따라서, 절편은 1에 가까울 것이며, 1에서 벗어난 만큼을 bias 로 판단하겠다는 의미를 가진다.
Bivariate LD score regression
두개의 trait X, Y 에 대한 test statistics 를 이용해 LD score regression 을 하는 것을 Bivariate LD score regression 이라고 한다. 구체적으로, 두개의 trait X, Y 에 대한 각각의 z-value 의 곱에 대하여 LD score regression 을 한다. 앞선 LD score regression 에 대해서는 chi-square value 를 사용했는데, chi-square value 는 z-value 의 곱이다. 즉, z^2 대신에 z_x * z_y 를 넣어서 regression 을 한다는 것이다.
참고) X_n 이 표준정규분포로부터 추출된 random variable 일 때, X_n 의 제곱의 합은 자유도가 n인 chi-square 분포를 따른다.
위에서는 자유도가 1인 chi-square value 이기 때문에 z^2 = chi-square 가 된다.
$$ X^2_1 + X^2_2 + ... X^2_n \sim \chi^2(n) $$
이 때의 기울기는 무슨 의미를 가질까? 만약 두개의 z-value 간에 아무런 연관성이 없다면, 1을 중심으로 퍼져있는 분포를 나타내게 된다. (z^2 의 분포는 자유도가 1인 카이제곱 분포를 따르며, 자유도가 1인 카이제곱 분포의 기댓값은 1이기 때문) 하지만, z-value 간에 연관성이 있다면, 기울기를 갖게 되며, 이 때의 기울기는 두 trait 간의 유전적 연관성을 의미한다. 두 trait 간에 유전적 연관성을 나타내는 지표로 co-heritability 가 있다. 기울기는 co-heritability 를 반영한다고 볼 수 있다. 이를 모델링하면 아래와 같이 표현할 수 있다.
genetic score, heritability, co-heritability, genetic correlation 관련 개념 정리
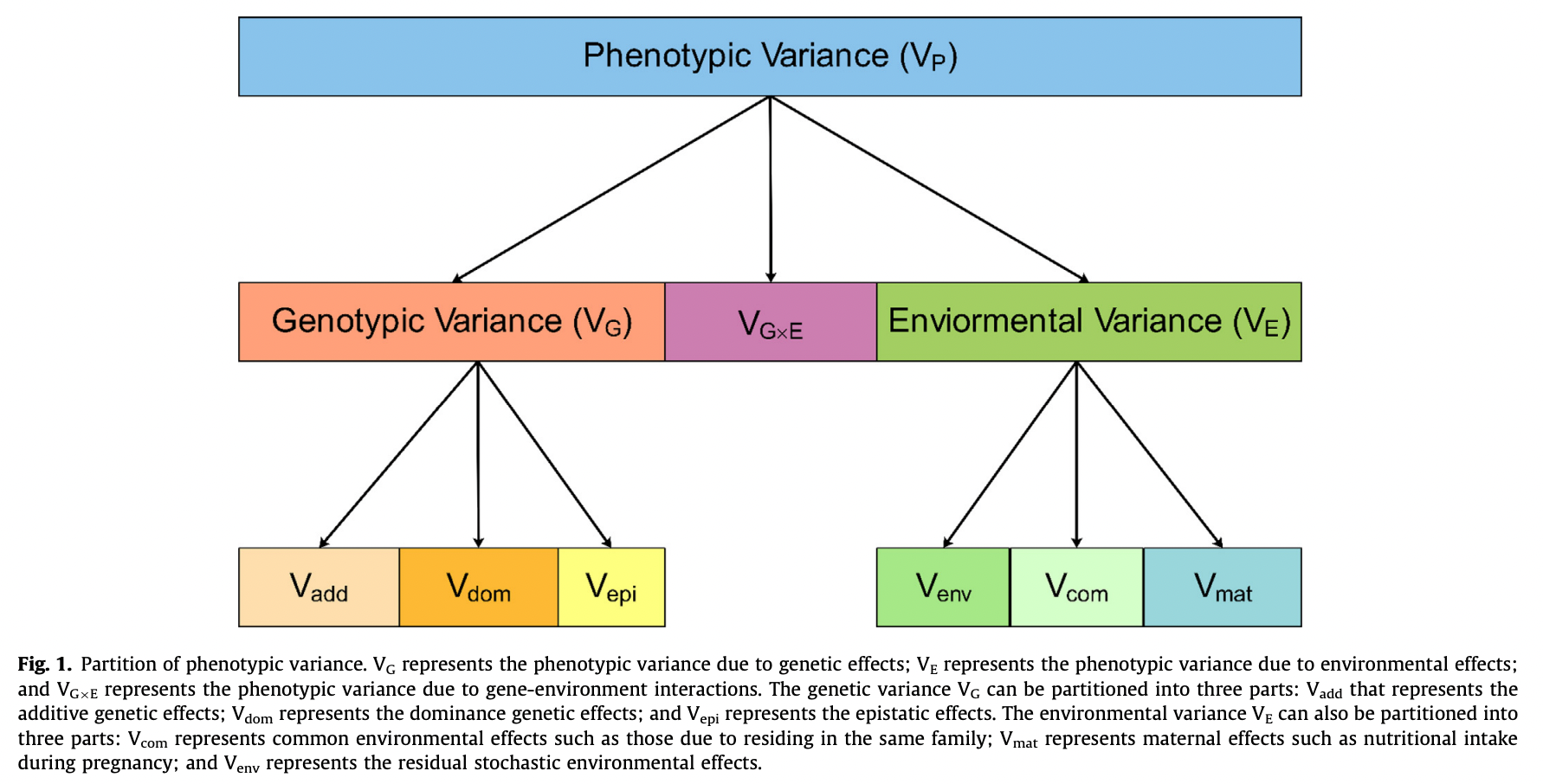
phenotype variance 의 분해. 본 문서에서는 , G 와 E만 고려한다.
phenotype Y 의 분산은 genetics 로 설명되는 분산과 environment 로 설명되는 분산으로 나누어진다. 유전율 (heritability) 는 phenotype(또는 trait) 의 분산에서 genetics 를 통해 설명되는 분산을 의미한다. heritability 는 0~1 사이의 값을 가진다.
$$ Var(Y) = Var(G) + Var(E) $$
$$ h^2 = Var(G)/Var(Y) $$
genetics 로 설명되는 분산이란 무엇일까? phenotype 을 예측하기 위해 유전정보를 이용해 어떠한 score 를 만들고, 이를 genetic score 라고 하자. genetic score 는 phenotype 에 대한 예측 값이며, 이 값이 높을 수록 phenotype 의 값이 높을 가능성이 높음을 의미한다 (만약 질병과 같은 binary trait 인 경우, 질병의 걸릴 가능성이 높음을 의미한다.)
genetic score 는 유전체 정보를 이용해 구한 phenotype Y 에 대한 예측값이다. 따라서 아래와 같이 쓸 수 있는데 heritability 의 식이 결정계수의 식과 닮아 있음을 알 수 있다. 결정계수는 전체 분산중 어떠한 모델을 통하 예측값의 분산이 차지하는 비율이며, 이것이 곧, 모델을 통해 설명되는 분산을 의미한다.
$$ h^2 = Var(\hat{Y}) / Var(Y) = r^2 $$
genetics 로 설명되는 분산은 genetic score 의 분산으로 정의할 수 있다. 만약 genetic score 를 구할 때, additive genetic effect 만 고려하여, additive genetic score 를 구해 heritability 를 구한 것을 narrow-sense heritability 라고 한다.
$$ h_n^2 = Var(AG)/Var(Y) $$
만약 , Y 가 standardization 이 되어 있다고하면, Y의 평균은 0이고, Y의 분산은 1이다. 그러면, 간단히, additive genetic score 의 분산이 바로 narrow sense heritability 가 된다.
"If the traits are standardized (that is, phenotypic variance = 1) and the genetic values consider only the additive genetic effects, then the genetic variances are narrow-sense heritabilities."
$$ h_n^2 = Var(AG) $$
두 가지 trait 의 유전적인 연관성을 정량적으로 표현하는 지표로 coheritability 라는 개념이 있다.
"Co-heritability is an important concept that characterizes the genetic associations within pairs of quantitative traits."
co-heritability 는 아래와 같이 정의되며, -1~1 사이의 값을 가진다.
$$ h_{x,y} = \frac{Cov(g_x,g_y)}{Var(X)Var(Y)} $$
이 식의 의미를 살펴보면 분자의 covariance 에 Cov(X,Y) 가 오게 된다면, pearson 상관계수와 같음을 알 수 있다. 이 식은 Cov(X,Y) 대신에 X,Y 에 대한 genetic score 를 대입시킴으로써, 두 trait 의 유전적 상관성을 표현했다고 볼 수 있다. 여기서도 마찬가지로 trait X,Y 를 평균이 0이고 분산이 1인 표준화된 trait 을 사용했다면, Var(X) = Var(Y) = 1 이기 때문에 아래와 같다.
$$ h_{x,y} = Cov(g_x,g_y) $$
두 가지 trait 의 유전적인 연관성을 정량적으로 표현하는 지표로 genetic correlation 이라는 개념도 있다. genetic correlation 은 아래와 같이 정의된다.
"The genetic correlation is a quantitative genetic parameter that describes the genetic relationship between two traits"
위 식은 pearson 상관계수의 식과 같으며, genetic correlation 의 통계적인 의미는 X,Y 의 genetic score 상관성 (pearson 상관계수) 라고도 할 수 있다. 만약 두가지 trait, 예를 들어 키와 발가락 길이의 유전적 연관성이 높다라고 한다면, 유전자를 통해 예측한 키 (키에 대한 genetic score) 와, 예측된 발가락 길이 (발가락 길이의 genetic score) 의 연관성이 높을 것이다. 이를 수치화한 것이 genetic correlation 이라고 볼 수 있다. genetic correlation 도 마찬가지로 -1~1사이의 값을 가진다.
genetic correlation 과 co-heritability 모두, 두가지 trait 의 유전적 연관성을 표현한다. 둘의 차이점은 무엇일까? trait X,Y 가 표준화 되어있다고 하면 genetic correlation 은 아래와 같이 정의된다. 아래 식을 보면, genetic correlation 은 co-heritability 가 X,Y 각각의 trait 의 heritability 로 보정된 식임을 알 수 있다.
$$ \rho_g = \frac{h_{x,y}}{\sqrt{h^2_x h^2_y}} $$
따라서, 두 trait 의 heritabilty 값이 작더라도, genetic correlation 은 높을 수 있다. 예를 들어, 발가락 길이와 키의 heritability 가 10% 라고 하자 (실제로는 더 높을 것이나 예시임). 즉, 전체 분산에서 genetic score 의 분산이 차지하는 부분이 10% 이다. 하지만, 두개의 genetic score 의 연관성이 높다라고 하면, genetic correlation 은 높게 추정될 수 있다. 따라서, genetic correlation 을 해석할 때, trait 을 genetics 가 설명하는 비중 (heritability) 도 함께 고려해야할 필요가 있다.
참고자료
- Genetic correlations of polygenic disease traits: from theory to practice, Nature review genetics, 2020
- Optimal Estimation of Co-heritability in High-dimensional Linear Models
- Statistical methods for SNP heritability estimation and partition: A review
def myConcat(*cols):
concat_columns = []
for c in cols[:-1]:
concat_columns.append(F.coalesce(c, F.lit("*")))
concat_columns.append(F.lit("\t"))
concat_columns.append(F.coalesce(cols[-1], F.lit("*")))
return F.concat(*concat_columns)
# combined column 에 모든 변수를 \t 로 concat 한 값 저장
data_text = data.withColumn("combined", myConcat(*data.columns)).select("combined")
data_text.coalesce(1).write.format("text").option("header", "false").mode("overwrite").save(path)